Языки программирования q и kdb+ привлекают внимание специалистов своей уникальной архитектурой и мощными возможностями для работы с большими наборами данных, особенно в финансовой сфере. Однако, несмотря на растущую популярность больших языковых моделей (LLM) в автоматизации написания кода, работа с такими языками как q остаётся сложной задачей. Основная причина кроется в особенностях синтаксиса и порядка выполнения кода, который радикально отличается от привычного большинству разработчиков и ИИ. В то время как привычные языки программирования, например Python или JavaScript, опираются на левосторонний порядок выполнения с учётом приоритета операторов, q и его предшественники — языки APL, J, k — имеют уникальный порядок исполнения: справа налево без приоритетов операторов (RL-NOP). Это означает, что выражения интерпретируются и вычисляются с конца, что кардинально меняет синтаксический и семантический смысл кода.
Понимание этой тонкости крайне важно, поскольку ошибки, вызванные неверным пониманием порядка, приводят к неправильной интерпретации логики программ и ошибкам при вычислениях. Например, распространённая ошибка при записи формулы Ньютона в q/kdb+ заключается в отсутствии скобок, которые в Python не являются критическими, а в q принципиальны для правильного вычисления. Конкретно: в Python выражение выглядит как 0.5 * y + x / (2 * y), тогда как в q корректным будет (0.5 * y) + x % 2 * y, поскольку оператор деления (%) обрабатывается иначе и выполняется справа налево.
Из-за такого кардинального отличия модели вроде Claude часто выдают код, смешанный из обоих стилей, что делает его неверным с точки зрения синтаксиса и логики обеих языков. Подобные трудности связаны с тем, что LLM ориентируются на левосторонний иерархический, прецедентный поток, на котором обучено большинство их данных. Они не «думают» справа налево — поток синтаксического анализа и генерации разрабатывался под традиционные языки программирования, поэтому модели с трудом справляются с RL-NOP концепцией. Основатель APL Кен Айверсон, обладатель премии Тьюринга, аргументировал выбор порядка справа налево как естественный путь восприятия сложных выражений, облегчая чтение и понимание их слева направо. Это также позволяет использовать более полезную семантику для определённых функций, в частности неассоциативных, при агрегации элементов коллекций.
Но с точки зрения современных моделей ИИ это является существенным вызовом. Помимо алгоритмических сложностей, есть ещё и вопрос отображения таких языков и визуальной презентации, особенно в контексте правосторонних языков, таких как арабский или иврит. Но даже при правильной визуализации направление написания справа налево — это не просто отображение текста, а порядок генерации токенов. Именно поэтому при работе в интерфейсе Claude Code CLI можно наблюдать неправильное расположение ряда символов в переводах на иврит. Аналогично перевод выражений q требует не обычного реверса текста, а работы с AST (абстрактным синтаксическим деревом), что намного сложнее.
Модель должна интерпретировать исходный код справа налево, корректно анализировать структуру вызовов и операций, а затем преобразовывать их в знакомую ей левостороннюю схему, например Python. Пример с вложенными функциями прекрасно иллюстрирует это: при преобразовании цепочек вызовов с q-моделями LLM часто неправильно меняют внутренний порядок, создавая неправильный порядок временных переменных. Это сравнимо с попыткой писать будущее, не написав сначала настоящее. В общем, текущие ИИ-модели не умеют эффективно создавать и обрабатывать код, где порядок операций фундаментально иной. Даже обучение с цепочкой рассуждений (chain-of-thought) пока не решает проблему полностью, показывая, что проблема заложена глубже в архитектуре и обучении моделей.
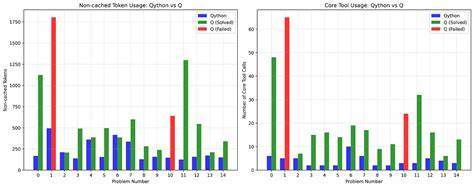
Кроме того, на исправление таких поведенческих особенностей не влияет масштаб или время: рынки и экономические интересы направлены на более популярные языки, и q/kdb+ остаются нишевыми с очень маленькой долей пользователей. Объём публично доступных данных с кодом q относительно мал, что ещё больше ограничивает возможности обучения. В совокупности этих причин нет больших шансов на то, что крупные игроки инвестируют ресурсы в кардинальные изменения архитектуры и обучение ИИ, чтобы сделать их полноценными q-кодерами. Тем не менее, выход есть в виде своеобразного компромисса — создания промежуточного языка, который совмещает в себе знакомую синтаксическую структуру, например Python, и логику q. Такой язык был предложен под названием Qython.
Он функционирует как мост: человек или ИИ пишет код в Qython, используя понятный и привычный для моделей синтаксис и порядок операций, а специальный транслятор преобразует этот код в истинный q, при этом корректно учитывая особенности порядка выполнения и операторы. Примером служит определение функции факториала в Qython, которая затем компилируется в корректный q-код. Это позволяет использовать возможности LLM, не заставляя их напрямую работать с нестандартным порядком обработки выражений. Так можно избавить ИИ от необходимости одновременно владеть двумя различными подходами и сосредоточиться на знакомом языке, а все тонкости конвертации и порядка реализовать в отдельном ПО. Использование такой технологии помогает обходить фундаментальные ограничения и позволяет комбинировать сильные стороны ИИ и уникальные возможности q/kdb+, открывает перспектива масштабирования автоматизации разработки на этих языках.
Важно отметить, что разработка подобного переводчика — не тривиальная задача. q не имеет единого и подробного опубликованного синтаксиса, а его операторная перегрузка и динамические типы данных усложняют создание универсального преобразователя кода. Поэтому требуется дополнительно использовать ИИ для анализа типа и логики кода с целью точного преобразования. Это направление активно разрабатывается и может в будущем значительно облегчить разработку и сопровождение проектов на q/kdb+. В целом же, проблема неспособности LLM полноценно писать на q/kdb+ связана с архитектурными особенностями языков, редкостью данных для обучения и приоритетами рынка.