В условиях современного цифрового мира с постоянно растущими объемами данных эффективная обработка аналитических запросов становится ключевым фактором успеха для бизнеса и науки. В этой связи выбор подходящего SQL-движка для работы с большими объемами информации критически важен. Одним из наиболее авторитетных и объективных способов оценки производительности таких движков является эталонный тест TPC-DS, который имитирует реальную нагрузку и сложные аналитические запросы на масштабируемых данных. В 2025 году команда специалистов провела сравнительное исследование трех популярных систем: Trino версии 476, Apache Spark 4.0.
0 и Hive 4, работающих на фреймворке MR3 версии 2.1. Тестирование проводилось с использованием объемного набора данных размером 10 терабайт, что позволяет получить представление о поведении систем в условиях реальной промышленной нагрузки. Одной из главных целей исследования было выяснить, насколько современный Hive, построенный на MR3, способен конкурировать с традиционно быстрыми MPP-системами, такими как Trino, а также оценить позицию Spark, который долгое время считался стандартом для обработки больших данных благодаря своей универсальности и глубокой интеграции с экосистемой Hadoop. При анализе результатов было отмечено, что все три системы успешно завершили почти все тестовые запросы, продемонстрировав высокую стабильность и работоспособность.
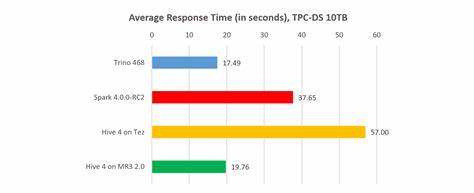
Тем не менее внутри этого общего показателя выявились существенные различия, которые напрямую влияют на выбор платформы в зависимости от задач бизнеса и бюджетных ограничений. Trino сохранил лидерство по скорости выполнения последовательных запросов, обработав весь набор из 99 тестовых задач за 4245 секунд. Это говорит о высокой оптимизации движка под низкую латентность и оптимальное использование распределенных ресурсов. Hive на MR3 близко последовал с результатом в 4299 секунд, показывая впечатляющий прогресс по сравнению с предыдущей версией, которая не достигала таких скоростей. При этом Spark отстал, уступая с существенным лагом в 15 266 секунд, что свидетельствует о необходимости дополнительной оптимизации для сложных аналитических нагрузок.
Особое внимание заслуживает среднее время отклика на запрос, рассчитываемое с использованием геометрического среднего, что позволяет нивелировать влияние выбросов и аномалий. По этому показателю Trino также оставался лидером с 17,46 секунд, однако Hive показал очень близкий результат — 17,84 секунд, улучшившись на 10% с прошлого релиза. Spark в этом параметре значительно уступал, демонстрируя почти вдвое больший показатель, что может усложнить работу при высокой интерактивной нагрузке. Интересным аспектом исследования стала оценка конкуренции при многопоточном режиме работы — потребительские нагрузки с одновременным запуском 10, 20 и 40 клиентов — что приближает модель теста к реальным сценариям эксплуатации в корпоративных средах. Здесь Hive на MR3 стабильно доминировал, показывая максимальную устойчивость и эффективность: при 40 одновременных пользователях система завершала запросы за 7802 секунды, опережая Trino почти на 25% и Spark более чем на 60%.
Данная производительность объясняется способностью MR3 эффективно балансировать ресурсы и распределять нагрузку, обеспечивая меньшую дисперсию времени выполнения и более ровное использование вычислительных мощностей. Глубокий анализ архитектурных решений позволил понять причины выявленных результатов. Trino строится на базе MPP (Massively Parallel Processing) архитектуры с push-моделью передачи данных, которая изначально нацелена на максимальное ускорение обмена между узлами путем активной пересылки. Эта модель отлично оптимизирована под минимизацию задержек, однако характеризуется сложностями в реализации надежного отката при сбоях и часто вынуждает повторно выполнять всю задачу при ошибках. Для решения подобных проблем Trino начал использовать промежуточную материализацию данных на распределённом хранилище, несмотря на изначальную ориентацию на чистую in-memory работу.
Напротив, Hive на MR3 базируется на MapReduce-архитектуре с pull-моделью, где потребители запрашивают необходимые данные у производителей, а промежуточные результаты сохраняются на локальных дисках. Этот подход изначально ориентирован на устойчивость, позволяя автоматически восстанавливаться после сбоев — ключевой плюс для корпоративных систем, требующих высокой надежности. В то же время традиционно считается, что такая архитектура уступает MPP по производительности из-за дополнительной работы с диском и менее эффективного обмена данными. Тем не менее MR3 в определённой степени сумел устранить этот компромисс, внедрив ряд оптимизаций, включая хранение промежуточных данных в памяти, что существенно сокращает задержки без потери гарантий fault tolerance. Таким образом Hive на MR3 удается использовать сильные стороны MapReduce — надежность и устойчивость — сочетая их с высокой производительностью, традиционно присущей MPP-системам.
Spark, который длительное время позиционировался как универсальное средство для кластерной обработки данных, продемонстрировал в тестах относительно низкую скорость по сравнению с двумя конкурентами. Это отчасти связано с общим неизменным характером его архитектуры, а также тем, что Spark пытается покрыть очень широкий спектр задач, не всегда посвящая ресурсы глубокой оптимизации именно для тяжелых аналитических SQL-запросов. Тем не менее Spark остается востребованным благодаря богатой экосистеме инструментов и гибкости настроек. Ключевым выводом из исследования можно считать то, что подход MapReduce с моделью pull и архитектурой MR3, который до недавнего времени воспринимался как устаревший из-за более низкой производительности, сегодня успешно конкурирует с современными MPP системами, сопоставимыми с Trino. Подобная эволюция открывает потенциальные возможности для предприятий, которым важен баланс между надежностью и скоростью выполнения сложных аналитических сценариев.
Тест TPC-DS, в применении к масштабу данных в 10 терабайт и набору из почти ста высококомплексных запросов, подтвердил, что выбор SQL-движка должен опираться не только на показатели отдельного запроса, но и на способность системы эффективно работать в конкурентной многопользовательской среде, справляться с отказами и обеспечивать стабильную производительность на больших кластерах. Для пользователей и компаний, которые ищут решения для аналитики больших данных, результаты данного сравнительного исследования могут служить надежным ориентирами. Если приоритетом является максимальная скорость на последовательных запросах и наличие определенных ограничений по fault tolerance, то Trino сохраняет лидерство и является привлекательным вариантом. В случаях, когда необходима надежность, устойчивость к ошибкам, а также отличная производительность при высокой конкуренции запросов, Hive на MR3 2.1 становится оптимальным выбором, способным обеспечить баланс этих требований.
Spark же может оставаться выгодным для многообразных рабочих нагрузок и интеграции с экосистемами Hadoop, но требует дополнительных настроек и улучшений для достижения сопоставимых по скорости результатов. В стратегии развития SQL-движков наблюдается явный тренд на скрещивание идеальных свойств различных архитектур. В частности, MR3 выступает примером эффективного объединения преимуществ MPP и MapReduce, позволяя не жертвовать производительностью ради отказоустойчивости и наоборот. Это открывает дверь к новым решениям и инновационным системам, способным преодолевать исторические ограничения. В свете итогов тестирования TPC-DS 2025 года можно смело утверждать, что технологии обработки больших данных в следующем десятилетии будут основываться именно на таких гибридных подходах, обеспечивающих как скорость выполнения, так и устойчивую работу при максимальных нагрузках.