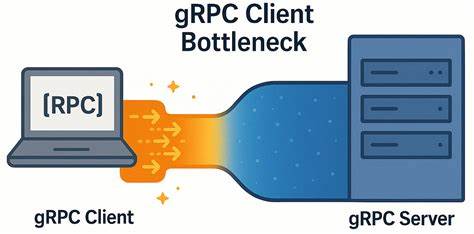
В современном мире высокопроизводительных распределённых систем gRPC становится одним из самых популярных решений для взаимодействия между сервисами благодаря своей производительности, надёжности и поддержке стриминга. Однако, несмотря на все преимущества, в сети с низкой задержкой могут возникнуть неожиданные ограничения, влияющие на итоговую производительность и задержку передачи данных. В частности, инженеры YDB, работающие с открытой распределённой SQL-базой данных, столкнулись с удивительным фактом — узкое место при высоких нагрузках находилось не на серверной стороне, а на стороне gRPC клиента. Это открытие изменило понимание того, как правильно оптимизировать клиентскую часть для достижения максимальной отдачи от сети и оборудования. В представленном исследовании подробно рассмотрен феномен возникновения задержек на клиенте и предложены пути решения, позволяющие достичь баланса между высокой пропускной способностью и минимальной латентностью при работе с gRPC.
Ключом к пониманию проблемы стала природа работы gRPC, который построен поверх HTTP/2 и использует мультиплексирование RPC-запросов внутри одной TCP-сессии. Каждый канал gRPC, создаваемый для подключения к серверу, по умолчанию использует один TCP-соединение. При одновременном выполнении большого количества запросов (так называемых in-flight) они мультиплексируются внутри этого соединения. У HTTP/2 есть ограничение на количество параллельных потоков (обычно около 100), и когда счётчик активных потоков достигает этого порога, новые запросы начинают ждать в очереди. В теории это может быть решено через создание нескольких каналов, каждый со своими TCP соединениями, тем самым распределяя нагрузку.
Однако, как показало тестирование, простое создание нескольких каналов с одинаковыми параметрами не дает желаемого эффекта — все они продолжают использовать одно и то же TCP-соединение. Лишь при указании разных параметров при создании каналов или включении специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL каналы получают отдельные соединения, что позволяет полностью раскрыть потенциал пропускной способности. Для исследования проблемы был разработан микробенчмарк — grpc_ping_server и grpc_ping_client — который выполняет простые пинг-запросы с минимальной нагрузкой на бизнес-логику. Тестирование проходило на двух отдельных серверах с мощными процессорами Intel Xeon Gold и 50 Гбит/с сетью с минимальной задержкой. В классическом сценарии с одним соединением результаты выявили существенное отставание от теоретически возможного уровня производительности.
Увеличение количества одновременных запросов сказывалось на времени отклика, которое росло пропорционально числу in-flight запросов, несмотря на почти полное отсутствие сетевых заторов и минимальные накладные расходы на уровне TCP. Анализ трафика показал, что спустя отправку пакета и его подтверждение ожидается небольшой период простоя в 150-200 микросекунд, который напрямую снижает общую скорость работы. Была выявлена внутренняя блокировка, связанная с мультиплексированием внутри одного TCP-соединения и взаимодействием внутри gRPC клиента. Это ограничение существенно влияет на производительность современного высокопроизводительного софта, где минимальные задержки критичны. Исследователи подтвердили, что подобное поведение проявляется не только в C++ реализации, но и в Java клиентах, что указывает на общую природу проблемы во всех основных реализациях gRPC.
Чтобы преодолеть эту границу, команда YDB ввела двухэтапный подход: создание отдельного канала для каждого рабочего потока, а также настройку каналов с уникальными аргументами либо активацию локального пула сабканалов. Это позволило обеспечить каждому каналу собственное TCP-соединение без мультиплексирования трафика внутри одного соединения. Итогом такой конфигурации стало заметное улучшение производительности — в 6 раз для обычных RPC и почти в 4.5 раза для стриминговых запросов, а рост задержки при увеличении количества параллельных запросов стал гораздо менее выраженным. Дополнительное тестирование в сети с более высокой задержкой (около 5 миллисекунд) показало, что влияние client-side bottleneck существенно снижается, а многоканальный подход даёт лишь небольшое преимущество при высоком числе одновременных запросов.
Это ещё раз подчёркивает важность данного исследования именно для условий современных быстрых дата-центров и кластеров. Эксперименты явно продемонстрировали, что для систем, работающих в условиях низкой сетевой задержки и высокой пропускной способности сети, критично избегать централизованного ограничения параллелизма в рамках одного TCP-соединения gRPC. Игнорирование этого момента способно привести к тому, что весь кластер будет недогружен из-за ограничения производительности клиентской части, даже если сервер идеально масштабируется и сеть практически не создаёт узких мест. Полученные выводы важны для разработчиков высоконагруженных систем, использующих gRPC в микросервисных архитектурах, распределённых базах данных и других сценариях с интенсивным взаимодействием между компонентами. Для практического применения важно внимательно настраивать количество каналов gRPC и учитывать возможность задания уникальных параметров канала для достижения реального мультиплексирования нагрузки.