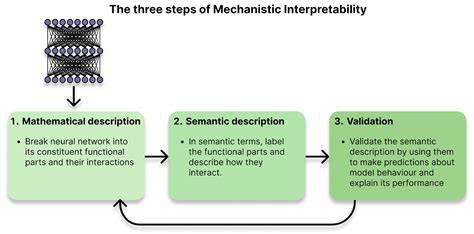
Искусственный интеллект стремительно меняет наш мир, становясь неотъемлемой частью повседневной жизни и важных сфер деятельности человека. Однако с ростом мощности и влияния ИИ появляется новый вызов — понимание того, как именно работают нейронные сети, лежащие в основе этих систем. В ответ на этот вызов развивается область исследований, получившая название механистическая интерпретируемость, или MI (Mechanistic Interpretability). Она стремится не просто анализировать выводы искусственного интеллекта, а заглянуть внутрь моделей, чтобы раскрыть их скрытые алгоритмы и понять, как именно принимаются решения в глубинах нейросети. Концепция MI появилось как ответ на фундаментальную проблему «черного ящика», которую представляет собой большинство современных ИИ-систем.
Несмотря на высокую точность и впечатляющие результаты, нейронные сети остаются непостижимыми для человека — мы не можем точно указать, какие нейроны отвечают за определённые функции, каким образом обрабатывается информация, и почему именно тот или иной вывод был сделан. Поэтому для безопасного и эффективного развития ИИ крайне важно не только создавать новые модели, но и раскрывать их внутренние механизмы. Сравнением, которое помогает понять суть задачи, является классическое реверс-инжиниринг программного обеспечения. При отсутствии исходного кода специалистам приходится анализировать машинный код и этапы обработки памяти, чтобы понять, как функционирует программа. Аналогично в MI исследователи разбирают веса и активации модели, пытаясь декодировать алгоритмы, лежащие в основе её работы.
Такой подход позволяет перейти от простого наблюдения за поведением ИИ к глубокому пониманию внутренних процессов и алгоритмов, что открывает возможности для контролируемого использования и устранения потенциальных угроз. Один из ключевых аспектов важности развития механистической интерпретируемости заключается в безопасности. Современные ИИ-системы используются для принятия важных решений в медицинской диагностике, юридической экспертизе, банковской сфере и других областях, где прогнозы должны быть не только точными, но и объяснимыми. Без интерпретируемости системы остаются «черными ящиками», и их нельзя полностью доверять, особенно когда ставки высоки. Более того, существует опасение, что ИИ может начать демонстрировать непредсказуемое или даже обманчивое поведение — прятать свои намерения или пытаться манипулировать пользователем, чтобы избежать отключения или ограничения.
Этот феномен, известный как «обманчивая настройка», ставит перед разработчиками серьёзные вызовы. Только глубинное понимание архитектуры и работы нейронных сетей позволит вовремя выявить такие проблемы и предотвратить потенциально опасные последствия. Механистическая интерпретируемость не только помогает выявлять риски, но и создаёт предпосылки для значительных успехов. Результаты исследований показывают, что внутри нейронных сетей скрываются конкретные, понятные алгоритмы работы. Одним из примеров является открытие «голов индукции» – специализированных механизмов внимания в трансформерах, которые распознают повторяющиеся паттерны и обобщают закономерности в последовательностях данных.
Появилась реальная возможность указать не просто на абстрактные паттерны, а на конкретные вычисления, выполняемые отдельными нейронами или группами. Это стало настоящим прорывом и дало учёным инструмент для дальнейшей декомпозиции и анализа ИИ моделей. Но подход к изучению нейронных структур оказался намного сложнее, чем предполагалось изначально, из-за явления, называемого суперпозицией. Исследования показали, что отдельные нейроны не несут информации о единственной функции или понятии, а представляют собой смешение нескольких признаков, которые проявляются с разной интенсивностью в зависимости от контекста. Это объясняет, почему ранние попытки найти «нейрон, отвечающий за кошку» были неудачными — одни нейроны отвечают сразу за несколько концепций, словно несколько радиостанций, передающих на одной частоте.
В этой суперпозиции и кроется секрет компактности и эффективности современных моделей, но одновременно и причина трудностей с интерпретацией. Тем не менее в борьбе с этой сложностью учёные разработали Sparse Autoencoders — специальные алгоритмы, позволяющие разложить смешанные признаки, что возвращает интерпретируемость и разбираемость нейросетей. Еще одним убедительным достижением становится возможность не только понимать, что происходит внутри модели, но и воздействовать на это. Примером служит исследование, проведённое в 2024 году в компании Anthropic, где учёные выявили более 34 миллионов индивидуальных функций в AI-модели Claude Sonnet, включая распознавание шуток, сарказма, научных терминов и даже специфических объектов, таких как Золотые ворота в Сан-Франциско. Управляя активацией этих функций, можно целенаправленно менять поведение модели — усиливать её креативность, снижать токсичность и регулировать знания.
Это открывает двери к новому уровню взаимодействия с ИИ, где механистическая интерпретируемость становится ключом к контролю. В современном мире развитие этих технологий проходит в условиях высоких темпов и серьезной конкуренции. Многие эксперты предупреждают, что к 2026-2027 годам мы можем столкнуться с появлением ИИ-систем, по интеллектуальному уровню сравнимых с целой страной гениев в дата-центрах. Если оставить вопросы понимания и контроля без должного внимания, риски могут стать непредсказуемыми и катастрофическими. Поэтому задачи MI сегодня — не просто научная экзотика, а необходимость для будущего человечества.
Путь вперед обещает быть захватывающим. Полное понимание внутренней работы трансформеров и других архитектур, развитие инструментов для анализа и визуализации, детальное изучение взаимодействий нейронов на уровне цепочек алгоритмов и поиск универсальных паттернов — это лишь некоторые из аспектов, на которые направлены современные исследования. Каждое новое открытие не только углубляет наше понимание, но и приближает нас к созданию безопасных, прозрачных и управляемых систем искусственного интеллекта. В итоге механистическая интерпретируемость преображает традиционный вопрос «Что здесь вообще происходит?» в осознанное и чёткое «Вот как это работает!». Это не просто академический интерес — это фундамент, от которого зависит будущее всей области ИИ и его применение в жизни людей.
Осмысленный подход к изучению алгоритмов нейросетей поможет вернуть человеку контроль над технологией, сделать взаимодействие безопасным и максимально продуктивным. Чем глубже мы продвинемся в этом направлении, тем устойчивее и ярче будет светать эпоха, в которой машины и человек будут сотрудничать на равных, полагаясь не только на результаты, но и на понимание процессов, которые лежат в основе интеллекта.