С момента появления алгоритма Adam, созданного Дамилем Кингма и Джимом Ба в 2014 году, он стал золотым стандартом для обучения нейронных сетей. Adam предлагал эффективный и надёжный механизм адаптивной оптимизации, который быстро завоевал популярность среди исследователей и практиков. Несмотря многочисленные попытки найти ему замену и улучшить этот метод, в течение многих лет Adam и его вариация AdamW сохраняли своё доминирующее положение. Однако последние годы показывают, что в области first-order оптимизаторов начинается новый этап — своего рода ренессанс, связанный с переосмыслением подходов и акцентом на практические результаты при обучении больших трансформерных моделей. Почему именно сейчас возникает такая тенденция? Ответ кроется в смене приоритетов исследовательского сообщества.
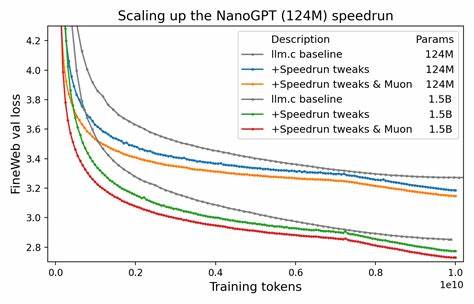
В 2010-х и начале 2020-х годов основное внимание уделялось поиску универсального решения, которое бы превосходило Adam по всем фронтам и подходило для широкого спектра задач и архитектур. Сейчас же фокус смещается с теоретических изысканий на прикладные результаты, особенно в контексте тренировки масштабных моделей, способных решать сложнейшие задачи обработки естественного языка. Это изменение парадигмы от «лучшей версии AdamW» к «оптимизатору, который лучше всего работает на больших трансформерах, обучающихся на объемных данных» стало ключом к успеху многих современных исследований. Одним из ярких примеров этих изменений является оптимизатор Muon, который демонстрирует впечатляющие показатели при обучении моделей NanoGPT и был активно использован в проекте Moonshot для тренировки их огромной модели Kimi K2. Уникальность Muon заключается в комплексном подходе, где оптимизация достигается не только за счёт самой математической формулы оптимизатора, но и благодаря общей доработке процесса обучения, учитывающей особенности трансформеров и специфику огромных датасетов.
Экспериментальный подход, который лежит в основе Muon и похожих разработок, контрастирует с более традиционными методами, ориентированными на теорию и абстрактные улучшения. Вместо бессмысленного сравнения с плохо подобранными версиями AdamW, исследователи берут хорошо настроенные реализации GPT и вносят целенаправленные изменения, стремясь ускорить обучение на практике. Такой подход помогает избежать распространённой проблемы, когда «улучшения» существуют лишь в теории или демонстрируются на упрощённых задачах, плохо отражающих реальные сценарии. Кроме Muon, активно развиваются и другие проекты, такие как Gluon и SPlus, которые расширяют идеи эмпирического создания оптимизаторов с учётом практики масштабного обучения трансформеров. Они утверждают, что именно тесная интеграция экспериментов и анализа реальных результатов позволяет выявлять истинные узкие места и устранять их эффективнее, чем попытки строго математически доказать преимущества нового метода до его испытания на практике.
Особенный интерес вызывают исследования, которые не ограничиваются только практическими улучшениями, но и привносят новые теоретические инсайты. Ярким примером служит работа над SPlus, в которой авторы открыто признают, что ключевые изменения в оптимизаторе возникли после детального экспериментального анализа, а уже затем была проведена глубокая теоретическая проработка. Такой симбиоз теории и практики отличается от классического подхода, когда сначала создаётся формальное обоснование, а затем исследуется эффективность алгоритма. Подобные тенденции напоминают феномен, описанный в книге «Искусство и страх», где приводится история фотографа Джерри Юльсманна. Он обнаружил, что студенты, которых оценивали по количеству снятых фотографий, стали не только более продуктивными, но и достигли более высокого качества работ.
Аналогично, оптимизационные исследователи сегодня, переключившись на эмпирический эксперимент и частые итерации на больших моделях, смогли добиться более глубокого понимания не только практических аспектов, но и теоретических основ оптимизации. Это событие нельзя рассматривать как временный тренд, скорее это начало новой эпохи в области оптимизации нейронных сетей. Оптимизаторы больше не создаются «в вакууме», ориентированные только на абстрактные свойства. Сейчас они становятся продуктом живого цикла исследований, основанного на сложных экспериментах и постоянной обратной связи с реальными задачами, такими как обучение триллионных параметров трансформеров на триллионных токенах. Новые оптимизаторы выходят за рамки традиционных first-order методов, сочетая адаптивность, устойчивость к шуму и гибкое подстраивание под структуру данных и архитектуры моделей.
Совместно с улучшением аппаратного обеспечения и методов масштабирования обучение крупных моделей становится всё более стабильным и эффективным. Это открывает перспективы для создания ещё более мощных систем искусственного интеллекта, способных генерировать текст, обрабатывать изображение, делать выводы и принимать решения с качеством, ранее недостижимым. В итоге, шаг за шагом мы движемся к завершению эпохи, в которой AdamW оставался непререкаемым лидером сферы оптимизации. Вместо этого на сцене появляются новые инструменты, родившиеся в огне практических испытаний и подкреплённые строгой научной критикой. Этот сдвиг обещает не только ускорить разработку и внедрение усовершенствованных моделей, но и вдохнуть новую жизнь в научные исследования, задавая свежие вызовы и открывая горизонты для понимания сути оптимизации в сложных системах.
Все эти изменения вместе формируют своеобразный ренессанс first-order оптимизаторов — эпоху, в которой практика и теория работают в тесной связке, ускоряя развитие искусственного интеллекта. Для исследователей, инженеров и энтузиастов в области машинного обучения сейчас наступает уникальный момент, когда инновации становятся особенно значимыми и быстрыми. Следить за этими процессами и принимать в них участие — значит быть на передовой технологического прогресса, определяющего будущее многих сфер человеческой деятельности.