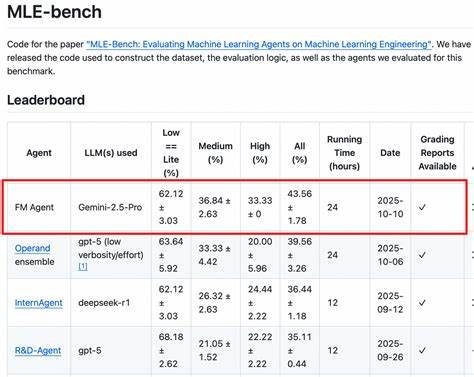
В современном цифровом мире, где информация передается и отображается на множестве устройств и в различных языковых средах, вопрос правильного представления символов становится крайне важным. Столкнувшись с необходимостью объединить огромное разнообразие алфавитов, знаков и символов, разработчики стандарта Unicode создали целый набор знаков, охватывающий практически все существующие системы письма. Однако представлять каждый символ понадобилось в виде последовательности бит - задача, которую умело решил стандарт UTF-8. Он стал одной из самых популярных и универсальных кодировок в мире благодаря своему гениальному дизайну и гибкости. Ключевой особенностью UTF-8 является то, что она представляет собой переменноширинную кодировку, способную поддерживать от одного до четырех байтов на символ.
Это значит, что базовые символы, знакомые нам из ASCII, занимают всего один байт, тогда как более сложные, редкие или современные иероглифы, эмодзи и специальные знаки кодируются более длинными последовательностями байт. В этом кроется загадка совместимости: файлы, содержащие только ASCII-символы, автоматически являются корректными UTF-8 файлами. Такое решение позволило легко адаптировать устаревшие системы, построенные на традиционном 7-битном кодировании, к современным требованиям интернационализации без потери данных и функционала. При этом, если файл содержит исключительно ASCII-символы, он также является и валидным ASCII-файлом. Технически первая часть байта в каждом символе служит указателем длины.
Если первый бит равен нулю, это один байт на символ, что полностью совпадает с ASCII. Если же последовательность начинается с определённого паттерна, например 110, 1110 или 11110, это означает, что символ занимает два, три или четыре байта соответственно. Следующие байты, как правило, начинаются с битового паттерна 10, указывая, что они являются продолжением текущего символа. Такое решение гарантирует, что программа для декодирования UTF-8 всегда может однозначно понять, где начинается и заканчивается один символ, даже если в потоке встречаются разные по длине последовательности. Влияние UTF-8 на индустрию интернета и информационных технологий сложно переоценить.
Большинство современных веб-сайтов, операционных систем, приложений и баз данных работают именно с этой кодировкой. Это позволяет избежать множества проблем, которые ранее возникали при обмене текстовой информацией между системами с разными локалями или старым программным обеспечением. Особый интерес вызывает то, как благодаря UTF-8 можно легко отображать эмодзи - яркие визуальные символы, ставшие неотъемлемой частью цифрового общения. На примере волновой руки 👋 можно конкретно увидеть, как один символ, представленный четырьмя байтами UTF-8, несет уникальный код из Unicode - U+1F44B. Такая универсальность достигается благодаря соглашению об использовании избыточных паттернов битов для кодирования большого диапазона символов без конфликта с базовыми ASCII.
Согласно официальной спецификации, UTF-8 покрывает все диапазоны Unicode, включая самые редкие языки, древние письменности и технические символы. Это большой шаг по сравнению с другими кодировками вроде UTF-16 или UTF-32, которые не обеспечивают обратную совместимость с ASCII и занимают фиксированное количество байт для каждого символа. Несмотря на то, что UTF-16 и UTF-32 имеют свои сценарии применения, их широко не используют для хранения текстов в интернете из-за проблем с совместимостью и увеличенным размером файлов. Помимо своей технической элегантности, UTF-8 активно продвигается как стандарт для международной коммуникации и хранения данных. Благодаря ему языковые барьеры цифрового пространства стали намного прозрачнее, что позволило значительно расширить доступ к информации, охватить множество этнических групп и культур.
Важно отметить, что UTF-8 не является единственным решением, которое поддерживает совместимость с ASCII. Существуют и другие кодировки, такие как GB 18030 для китайского языка, а также наборы ISO/IEC 8859. Однако их область применения гораздо уже, и они не обладают таким же уровнем универсальности и поддержки, как UTF-8. Нагрузив стандарты кодирования новыми требованиями, мир информационных технологий нуждался в устойчивом и гибком решении, которое позволило бы безболезненно эволюционировать от векового ASCII к беспрецедентной глобальной цифровой коммуникации. UTF-8, с его продуманной архитектурой, стал именно таким решением.
Для разработчиков и пользователей важен еще один аспект - прозрачность и понятность алгоритма декодирования. Принцип работы заключается в считывании байта, определении его класса по первым битам и считывании необходимого числа дополнительных байт. После чего биты этих байт объединяются для получения уникального числового идентификатора символа - кодовой точки, согласно Unicode. Этот процесс облегчает разработку программного обеспечения, позволяя создавать кроссплатформенные продукты, не опасаясь ошибок кодирования. На практике встречается множество инструментов для визуализации и экспериментов с UTF-8, например, специальные онлайн-площадки, которые позволяют пользователям вводить текст и видеть, как именно он кодируется в UTF-8 байтах.
Такие решения помогают изучать механизм кодировки, способствуют повышению грамотности в области текстовой обработки и программирования. Подводя итог, можно уверенно утверждать, что UTF-8 - это не просто набор технических правил, а действительно гениально сконструированная система, позволяющая объединить разнообразие языков и современную технологическую инфраструктуру. Ее успех обусловлен не только техническими достоинствами, но и философией обеспечения совместимости и гибкости. Без UTF-8 сегодняшняя интернет-среда и большинство цифровых коммуникаций, какими мы их знаем, просто не могли бы существовать во множестве своих вариаций. Эта кодировка стала мостом между прошлым и будущим информационного обмена, неподвластным времени и границам.
.

![Tesla Master Plan 4 [pdf]](/images/28E175F0-C2E6-478C-AA31-71EABB40EB18)