В последние годы развитие больших языковых моделей кардинально изменило способы создания текстов и решения сложных задач естественной речи. Традиционные авторегрессионные модели (ARMs), которые генерируют текст последовательно, по одному токену за раз, долгое время оставались основой индустрии. Однако появление нового класса диффузионных моделей (dLLM), работающих на основе итеративного устранения шума в зашифрованных участках текста, вызвало значительный интерес благодаря своей многообещающей эффективности и качеству генерации. Несмотря на заметный прорыв, диффузионные модели сталкиваются с серьезными проблемами в области производительности, причем долгие задержки при инференсе снижают их конкурентоспособность по сравнению с авторегрессионными подходами. Ключевой проблемой является то, что существующие методы ускорения, эффективно работающие с ARMs, не применимы к dLLM из-за их особенности — двунаправленного внимания, которое требует учета контекста и токенов одновременно с обеих сторон.
В таких условиях стандартный метод кэширования ключ-значение оказывается неприменим. В ответ на эту проблему группа исследователей разработала инновационный фреймворк DLLM-Cache, основанный на адаптивном кэшировании и оптимизации процессов вычислений во время инференса диффузионных моделей. Главная идея заключается в том, что во время последовательных этапов устранения шума в dLLM большая часть токенов сохраняется неизменной или сильно похожей между соседними шагами. Это можно использовать для повторного использования промежуточных вычислений и сокращения избыточности, которая традиционно возникает при каждом новом прогона модели. DLLM-Cache объединяет два важных компонента: долговременное кэширование статических частей подсказки (prompt) и частичное обновление динамического ответа, контролируемое по мере сходства признаков между соседними итерациями.
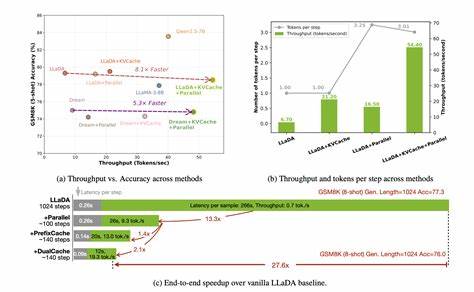
Такой механизм позволяет экономить вычислительные ресурсы, избегая повторного вычисления для неизменных участков и обновляя только те части, которые действительно претерпевают изменения. Отсутствие необходимости дополнительного обучения — ещё одно важное преимущество, что делает DLLM-Cache легко интегрируемой в существующие структуры и расширяющей потенциал их использования без необходимости в сложной перенастройке моделей. Экспериментальные проверки на нескольких значимых представителях диффузионных моделей — LLaDA 8B и Dream 7B — продемонстрировали впечатляющий эффект: ускорение работы до 9.1 раза по сравнению с традиционным инференсом без ущерба для качества генерации текста. Такое улучшение позволяет использовать dLLM даже в сценариях, где ранее доминировали авторегрессионные модели, снижая разрыв в производительности и открывая новые возможности для практического применения диффузионных технологий.
Технология DLLM-Cache актуальна не только для повышения скорости, но и с перспективой экономии энергопотребления и снижения затрат на вычислительные мощности — критически важных факторов в эпоху масштабных ИИ-моделей и роста их внедрения в повседневные задачи. В совокупности внедрение адаптивного кэширования в диффузионных языковых моделях может стать новой вехой в развитии области, обеспечивая баланс между качеством, скоростью и ресурсной эффективностью. Кроме того, открытый доступ к исходным кодам и материалам способствует быстрому распространению метода и стимулирует дальнейшие улучшения и инновации от сообщества исследователей и разработчиков. Важно отметить, что успех DLLM-Cache показывает потенциал для применения подобных адаптивных механизмов кэширования и в других типах моделей с похожими архитектурными особенностями и проблемами производительности. Это расширяет горизонты исследований в области оптимизации инференса, а значит, и ускорения трансформации ИИ-технологий в реальные приложения.
Следующим шагом в развитии данной технологии может стать ее интеграция с аппаратным обеспечением, что позволит добиться ещё большей скорости и эффективности, а также адаптация кэширования под различные задачи генерации, включая мультимодальные сценарии, где тексты сочетаются с изображениями и аудио. Таким образом, DLLM-Cache является знаковым достижением в сфере диффузионных больших языковых моделей, обеспечивая критически важное улучшение скорости и практичности применения этих инновационных технологий. Она открывает путь к более широкому распространению и внедрению dLLM в различные отрасли, от автоматизации контента и поддержки клиентов до творчества и научных исследований. В результате появление DLLM-Cache знаменует важный этап в развитии языковых моделей, где инновационные алгоритмы обработки данных встречаются с продвинутыми методами управления вычислительными ресурсами, формируя новое будущее генеративного ИИ.