В современном мире искусственного интеллекта обучение с подкреплением (Reinforcement Learning, RL) стало неотъемлемой частью развития умных систем. Оно открывает новые горизонты для решений сложных задач, которые невозможно эффективно решить классическими методами. Одним из важных вызовов в машинном обучении является проблема забывания - ситуация, когда модель, обучаясь новой задаче, теряет способность выполнять уже освоенные функции. В последние годы особенно ярко проявляется разрыв между методиками обучения с подкреплением и традиционным супервизированным fine-tuning, когда речь идет о сохранении прежних знаний при адаптации к новым условиям. При этом онлайн RL показывает удивительную устойчивость к забыванию, что вызывает интерес как у исследователей, так и у практиков.
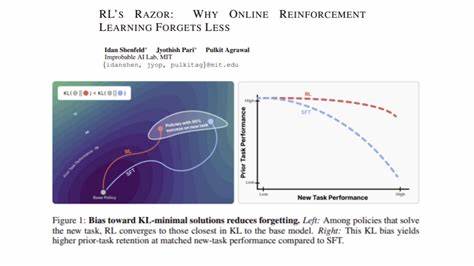
Недавнее исследование под названием "RL's Razor: Why Online Reinforcement Learning Forgets Less" раскрывает механизмы, позволяющие онлайн RL сохранять уже имеющееся понимание, ставя во главу угла не только производительность, но и минимальные изменения в политике поведения, что можно назвать принципом RL's Razor. В основе проблемы лежит понятие дистрибуционного сдвига. Когда модель обучается новой задаче, меняется распределение данных, с которыми она работает, а также сама политика (стратегия действий) модели. Чем значительнее это изменение, тем больше вероятность, что модель забудет ранее выученные паттерны и навыки. Как показывает исследование, ключевым индикатором изменений служит расхождение Кулбака-Лейблера (KL-дивергенция) между базовой политикой и новой, адаптированной под новую задачу.
Онлайн RL предпочитает обновления, которые минимизируют это KL-расхождение. Это значит, что она стремится сохранить свою прежнюю стратегию максимально близкой, внося только те изменения, которые необходимы для успешного решения новой задачи. Потому RL сохраняет баланс между освоением нового и сохранением старого опыта. В противоположность тому, супервизированное fine-tuning не ставит своей целью сохранение близости к исходной модели и может в итоге находить решения, радикально отличающиеся от базовой политики, что ведет к более быстрому и заметному забыванию. Такой подход может быть желательно при существенном изменении задач или целей, однако зачастую именно неизбирательное обновление становится причиной потери полезных навыков.
В исследовании было проведено множество экспериментов с крупными языковыми моделями и фундаментальными робототехническими моделями, подтверждающих теоретические выкладки. Результаты показывают, что при сохранении низкой KL-дивергенции модели, обучающиеся онлайн методом RL, демонстрируют более стабильное и надежное поведение, меньше подвергаются забыванию и лучше адаптируются к меняющейся среде. Теоретические обоснования базируются на свойствах он-политикового обновления, которые естественным образом ведут к переключению политики меньшими шагами в пространстве вероятностных распределений. Это приводит к тому, что модель не совершает резких изменений, а развивается мягко, плавно, при этом не жертвуя эффективностью на новой задаче. Таким образом, принцип RL's Razor можно интерпретировать как выбор самого простого и наименее изменяющегося пути для достижения новой цели.
Среди всех возможных решений, алгоритмы RL отдают предпочтение тем, что требуют минимальных отклонений от изначальной политики, эффективно пресекают забывание старого функционала и одновременно дают возможность осваивать новое. Практическое применение этого принципа особенно актуально для создания универсальных и долгоиграющих систем искусственного интеллекта, которым приходится часто адаптироваться к новым обстоятельствам без потери прежних компетенций. В робототехнике это гарантирует более надежную работу роботов в изменяющихся условиях, а для языковых моделей - стабильную память и способность сохранять накопленные знания даже в процессе обучения новым навыкам. Дополнительным плюсом онлайн RL является возможность интерактивного обучения в реальном времени, что расширяет рамки применения ИИ систем в промышленности, медицине и сервисах. Конечно, несмотря на преимущества, обучение с подкреплением требует значительных вычислительных ресурсов и сложной настройки, а также может сталкиваться с трудностями стабильности и сходимости.
Однако открытие принципа RL's Razor способно направить исследователей на поиск более устойчивых и адаптивных архитектур, где баланс между изучением нового и сохранением старого является залогом качества. Таким образом, современный подход онлайн обучения с подкреплением может рассматриваться не просто как метод повышения производительности, а как фундаментальный механизм минимизации забывания и сохранения знаний. Это открывает новые возможности для разработки систем ИИ, способных к долгосрочному обучению и адаптации, что является важным шагом на пути к созданию более совершенного и универсального интеллекта. Для тех, кто изучает машинное обучение и интересуется будущим искусственного интеллекта, понимание принципа RL's Razor является ключевым элементом, помогающим создавать более надежные и эффективные модели, способные учиться без утраты важной информации и навыков. В итоге онлайн обучение с подкреплением выступает как естественный фильтр, отсекающий чрезмерные изменения и сохраняя ту основу, на которой строится дальнейшее развитие моделей.
Такой подход обеспечивает не только высокое качество работы в новых задачах, но и психологически ближе к идее человеческого обучения - непрерывного наращивания знаний без потери уже освоенного. Внимание исследователей и разработчиков к этим особенностям онлайн RL с каждым днем растет, делая эту область одним из самых перспективных направлений в машинном обучении и искусственном интеллекте в целом. .







