Современные языки программирования постоянно эволюционируют, предлагая новые парадигмы и подходы к организации данных и управления потоками выполнения. Среди таких инноваций особое место занимает язык Qi, ориентированный на потоковое программирование. Его основная идея заключается в имплицитной передаче значений между шагами обработки, что создает удобный, лаконичный и выразительный код. Однако при работе с привязками значений к именованным идентификаторам возникают определённые трудности, связанные с порядком вычисления и областью видимости переменных. В этой статье мы рассмотрим концепции древовидных (tree) и ориентированных ацикличных графов (DAG) привязок и их значение для параллелизма и гибкости программ на Qi.
Qi, вдохновляясь идеями функционального и потокового программирования, использует так называемые формы потока или flow forms, где данные перетекают от одного шага к другому автоматически и без явного указания параметров. Такой подход напоминает исторические практики языков AWK или Perl, где значение специальной переменной $_ неявно присутствовало в контексте выполнения. Qi использует эту концепцию с улучшениями — здесь она не приводит к «write-only» стилю, а наоборот, способствует ясности и читаемости кода. Пример простого потока на Qi иллюстрирует передачу значения 10 через последовательность функций: генерация диапазона чисел, фильтрация нечётных чисел, возведение их в квадрат и суммирование результата. Такой конвейер вычисляет сумму квадратов всех нечётных чисел от 0 до 9.
Данный пример показывает, как потоковые вычисления минимизируют необходимость в явных переменных, используя возможность неявного threading. Тем не менее, реальная польза в программировании заключается именно в умении фиксировать промежуточные результаты. Qi позволяет делать это через привязки, используя ключевое слово as, что позволяет закрепить значение за определённым идентификатором и далее использовать его повторно. Такой подход напоминает классические let-выражения, но в Qi он реализован с особенностями, которые важно понимать. При использовании базового варианта привязок мы можем заметить, что они по сути ведут себя как let*.
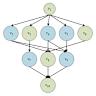
Это значит, что последовательные привязки зависят друг от друга в точном порядке, как если бы код был линейным деревом вычислений. Это упрощает понимание порядка вычислений и поддерживает строгую область видимости, однако вводит ограничение на параллелизм — каждый последующий шаг должен дождаться результата предыдущего, даже если с точки зрения бизнес-логики это не обязательно. Интереснейшие примеры проявляются при использовании формы tee, которая создает ответвления потока для параллельных вычислений. В случае с Qi эти ветви создают два параллельных потока для подсчёта суммы квадратов нечётных и чётных чисел соответственно. Однако, если мы хотим использовать результаты одной ветви в другой, возникает неявная зависимость, которая выстраивает вычисления в строгий порядок.
Такая модель привязок формирует не дерево с обычными ветвлениями, а линейную структуру, что сужает возможности и убивает потенциальный параллелизм. В частности, линейность модели let* означает, что каждая новая привязка видит все предыдущие, но обратное невозможно. Это приводит к тому, что даже для независимых ветвей необходимо ждать результата первой, чтобы приступить ко второй. Для небольших скриптов и последовательной логики это приемлемо, но при масштабировании и в системах с множестенным вычислительным ресурсом это ограничение существенно снижает производительность. Именно здесь появляется идея использования привязок в модели ориентированного ацикличного графа или DAG.
В отличие от дерева, DAG позволяет явно указывать зависимости между вычислениями и не ограничивает область видимости лишь линейным порядком. Такой подход поддерживает гибкость и повышает параллелизм, поскольку ветви с независимыми результатами могут обрабатываться одновременно без ожидания друг друга. Применение DAG-привязок в Qi откроет новые возможности для оптимизации потоков, позволяя конечному пользователю обозначать связи между идентификаторами явно, а не имплицитно. Это поможет добиться максимального использования параллельных вычислительных ресурсов и минимизировать задержки. Тем не менее, переход от древовидных привязок к DAG-привязкам требует изменения в лексической области видимости и управления зависимостями на уровне языка и среды выполнения.
Придется внедрять алгоритмы отслеживания зависимостей и безопасного одновременного исполнения, что является нетривиальной задачей. Будущее развития Qi связано именно с такими изменениями. На последних встречах разработчиков Qi обсуждалось добавление синтаксиса и семантики, позволяющих явно задавать зависимости между ветвями и создавать более сложные и эффективные модели вычислений. Это позволит сохранить выразительность и лаконичность языка, добавив при этом мощные инструменты для параллельного программирования. Резюмируя, переход от традиционных древовидных привязок к DAG-привязкам — это значительный шаг в развитии языка Qi и потоковых парадигм в целом.
Он расширяет возможности управления вычислительными потоками, способствует лучшей оптимизации и масштабируемости решений на базе Qi. Для разработчиков это означает больше контроля над зависимостями, возможность писать более чистый и эффективный код, а также ускорение выполнения за счёт распараллеливания. В конечном счёте, глубокое понимание различий между привязками, основанными на деревьях и ориентированными ацикличными графами, поможет создавать более продвинутые и производительные программы, использующие все преимущества современных вычислительных платформ. Следите за развитием Qi и новостями от сообщества, чтобы первыми узнать о внедрении DAG-привязок и открыть для себя новые горизонты потокового программирования.





![Sen. Warren on Mamdani: He's willing to try new ideas to bring down costs for NY [video]](/images/C761107C-37E9-4188-BAEA-FBE6BDB21D6F)