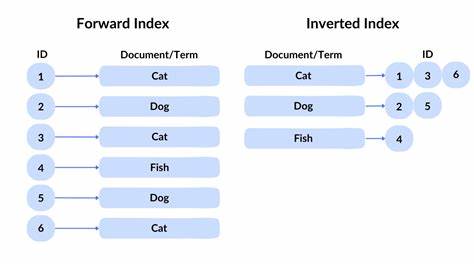
В современном мире цифровой информации количество текстовых данных растет с невероятной скоростью. Эффективный поиск по таким массивам текстов становится сложной задачей, требующей специальных подходов и структур данных. Одной из наиболее распространенных и эффективных структур, применяемых в поисковых системах, является инвертированный индекс. Этот элемент формирует фундамент для быстрого и точного поиска, особенно когда речь идет о больших объемах данных. Инвертированный индекс — это структура данных, которая позволяет быстро находить документы или записи, содержащие определенные слова или термины.
Если стандартный индекс книги показывает, где найти конкретную информацию в тексте, то инвертированный индекс делает обратное: он указывает, в каких документах встречается конкретное слово. Такая организация данных значительно ускоряет процесс поиска и является неотъемлемой частью технологий информационного поиска. Основы инвертированного индекса заключаются в том, чтобы для каждого термина сохранить список документов, в которых он встречается. При вводе поискового запроса система обращается к инвертированному индексу, получает перечень релевантных документов и отображает их пользователю. Такая структура особенно хорошо оптимизирована для полнотекстового поиска, где необходимо быстро определить все места, где встречается конкретное слово или фраза.
Процесс создания инвертированного индекса начинается с разбора текстовых данных. Тексты необходимо разделить на отдельные слова или токены, удалив при этом стоп-слова — самые распространенные и неинформативные слова вроде предлогов и союзов. Такой подход позволяет сократить размер индекса и повысить эффективность поиска. Стемминг и лемматизация — методы нормализации слов, благодаря которым слова сводятся к базовой форме. Это важно, чтобы релевантность поиска не зависела от грамматических форм и множества вариаций слова.
После разбиения текста на термины и их нормализации следует этап построения индекса. Для каждого термина создается запись, в которой хранится список идентификаторов документов, где этот термин встречается. Можно также сохранить позиции термина внутри документа, что позволяет реализовывать более сложные поисковые запросы, например, поиск по фразам и нахождение контекста вокруг ключевого слова. Хранение такой информации повышает точность и качество поиска. Оптимизация инвертированного индекса играет важную роль.
При работе с масштабными наборами данных важно эффективно сжимать индекс и минимизировать затраты памяти. Методы компрессии, такие как использование битовых векторов, сжатие по пробелам и другие алгоритмы кодирования, позволяют существенно уменьшить размер структуры данных без потери производительности. Реализация инвертированного индекса требует не только правильной структуры хранения данных, но и алгоритмов эффективного обновления. В динамических системах, где документы добавляются, изменяются или удаляются, индекс должен своевременно корректироваться. Решения включают использование промежуточных индексов, периодическую повторную индексацию, а также подходы с ведением нескольких уровней индексов для сокращения времени обновления.
Практическая реализация начинается с выбора языка программирования и подходящих хранилищ данных. Популярны варианты с использованием реляционных баз данных для хранения основной информации, дополненных специализированными структурами для работы с индексами. Однако для крупных проектов предпочтительны NoSQL базы, распределенные файловые системы и готовые поисковые движки, которые имеют встроенные средства работы с инвертированными индексами. Создание простого инвертированного индекса можно реализовать даже на базовом уровне с помощью словарей и хэш-таблиц. На вход подаются документы, которые разлагаются на термины, после чего наполняется структура словаря, где ключ — слово, а значение — список документов.
Такой подход подходит для начального понимания и тестирования. В действующих системах дополнительно следует учитывать параллельную обработку, обработку ошибок, масштабируемость и безопасность данных. Важно также продумать стратегию поиска с использованием инвертированного индекса. Поисковые запросы могут быть простыми, например, включать одно ключевое слово, или сложными, реализовывать логические операторы, фразы и фильтры. Эффективное выполнение таких запросов зависит от структуры индекса и алгоритмов обхода списков документов, что требует реализации сортировки, пересечений, объединения множеств и других операций.
Благодаря инвертированному индексу поисковые системы способны мгновенно выдавать результаты даже на миллионах документов. Такая структура востребована не только в интернет-поиске, но и в различных областях — электронных библиотеках, системах документооборота, базах данных и аналитических платформах. Понимание принципов работы и умение реализовать свой инвертированный индекс позволяет разработчикам создавать высокопроизводительные и масштабируемые решения. Таким образом, инвертированный индекс — ключевой элемент в современной информационной инфраструктуре. Его пошаговая реализация требует внимания к деталям, начиная от предобработки текста и заканчивая оптимизацией хранилища и обновлением данных.
Освоив этот процесс, можно значительно улучшить скорость и качество поиска, что особенно важно в эпоху больших данных и постоянного роста информационных потоков.