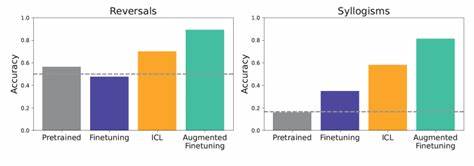
В эпоху быстрого развития искусственного интеллекта большие языковые модели (Large Language Models, LLM) становятся неотъемлемой частью многих отраслей, включая медицину, образование, маркетинг и программирование. Эти модели способны генерировать тексты, отвечать на вопросы, переводить языки и выполнять разнообразные задач благодаря своему умению понимать и воспроизводить человеческий язык. Однако, чтобы максимально раскрыть потенциал LLM в реальных условиях, необходима их адаптация под специфику конкретных приложений. В этой связи на передний план выходят два основных метода кастомизации моделей – тонкая настройка (fine-tuning) и обучение в контексте (in-context learning). Оба способа обладают уникальными характеристиками, подходами и целями, и понимание их отличий имеет критическое значение для успешного внедрения решений на базе ИИ.
Тонкая настройка заключается в дополнительном обучении предобученной модели на специализированных данных, которые отражают задачи и стиль, востребованные в определенной области. Процесс начинается с исходной версии модели, уже обученной на большом корпусе текстов, и затем проводится адаптация на узкотематичных данных. Это позволяет модели улучшить понимание специфической терминологии, стилевого оформления и логических связок, релевантных конкретному кейсу. Такой подход обеспечивает более последовательные и точные результаты, что крайне важно для бизнес-приложений, требующих высокого уровня надежности и соответствия правилам отрасли. Среди преимуществ тонкой настройки можно выделить возможность глубокой адаптации под задачи клиента, снижение ошибок, связанных с непониманием контекста, и повышение качества генерируемого контента.
Тем не менее, данный метод часто требует значительных вычислительных ресурсов и времени, особенно если модель имеет множество параметров. Помимо технических особенностей, существует и другая сложность – необходимость в большом объеме качественных данных, которые должны быть тщательно подготовлены и аннотированы. Это может стать ограничивающим фактором для небольших компаний или команд с ограниченным бюджетом. В противоположность этому обучение в контексте представляет собой метод, при котором модель не изменяет свои внутренние параметры, а вместо этого получает примеры или инструкции непосредственно в тексте запроса, позволяющие ей адаптироваться к задаче «на лету». Такой подход не требует дополнительного обучения модели, что значительно упрощает и ускоряет процесс кастомизации.
Пользователи могут предоставлять модели несколько примеров желаемого поведения или уточнять контекст задачи, и модель на основе этих данных формирует релевантный ответ. Обучение в контексте обладает заметной гибкостью и удобством в использовании, так как позволяет быстро переключаться между различными задачами без необходимости заново обучать модель. Это особенно полезно в сценариях, где задачи меняются динамично, а требований к бесконечному повторному обучению нет. Однако данный способ имеет ограничения по глубине и точности адаптации, так как модель не модифицируется внутренне и может не полностью учитывать тонкости задачи, что иногда приводит к менее последовательным или корректным результатам. В выборе между тонкой настройкой и обучением в контексте важна специфика задачи, рессурсы и конечные цели.
Если перед компанией стоит задача долгосрочной интеграции с высоким уровнем качества и точности, необходима тонкая настройка с использованием богатого набора отраслевых данных. В то же время для прототипирования, быстрого тестирования гипотез или проектов с ограниченными ресурсами оптимальным будет обучение в контексте, которое обеспечивает оперативное получение релевантных результатов. Кроме того, современные технологии всё чаще сочетают оба подхода, используя тонкую настройку как основу и обучение в контексте для оперативной настройки без дополнительного переобучения. Такой гибридный подход позволяет балансировать между качеством и скоростью, что особенно востребовано в коммерческих решениях и системах с изменяющимися требованиями. Факторами, влияющими на эффективность настройки LLM, являются качество и объем данных, вычислительные мощности, архитектура самой модели и цели применения.
Компании, инвестирующие в развитие ИИ, должны тщательно оценивать свои возможности и потребности, чтобы выбрать оптимальную стратегию адаптации, обеспечивающую не только высокую производительность, но и экономическую эффективность. В заключение, тонкая настройка и обучение в контексте представляют собой два мощных инструмента адаптации больших языковых моделей для реальных задач. Их грамотное использование способствует раскрытию потенциала ИИ, повышая качество взаимодействия с пользователями и расширяя функциональность приложений. По мере развития технологий и появления новых методов кастомизации возможности для персонализации LLM продолжат расширяться, открывая новые горизонты для бизнеса и науки.