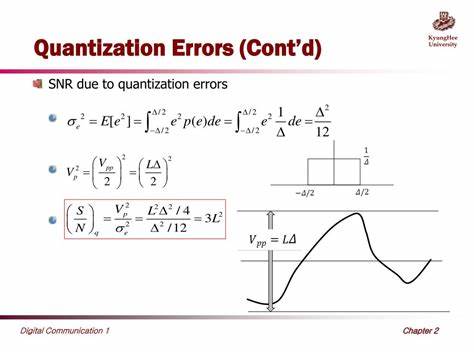
Квантование – это процесс преобразования значений из формата с высокой точностью в формат с более низкой точностью. На практике это означает, что данные, хранящиеся в 32-битных числах с плавающей точкой, переводятся в, например, 4-битные целочисленные значения. Такой подход широко применяется в различных областях – от сжатия звука и изображений до оптимизации нейросетей с целью уменьшения их размера и энергозатрат. Однако, как и любой процесс сжатия, квантование сопровождается потерями информации, которые проявляются в виде ошибок квантования. Что это такое и как ошибки влияют на конечный результат, разберемся более подробно.
Основная причина ошибок квантования кроется в том, что исходные данные содержат больше уровней или градаций, чем выбранный формат хранения. Представьте аудиофайл, который записан с глубиной 16 бит, где каждый отсчет может принимать 65536 возможных значений. При квантовании его до 8 бит количество уровней снижается до 256, и часть информации о нюансах звука неизбежно теряется. В результате появляются так называемые шумы квантования, которые на слух могут восприниматься как приглушенное или искажённое звучание. Аналогичные эффекты наблюдаются и в изображениях при уменьшении цветовой палитры.
Например, старые игры на 8-битных приставках использовали палитру из 256 цветов, что по сравнению с современными изображениями с миллионами оттенков выглядело непривлекательно – окраски стали менее плавными, появились цветовые полосы и резкие переходы, связанные именно с ограничением палитры.При этом стоит понимать, что квантование – не всегда негативный процесс. Благодаря снижению битности можно значительно уменьшить объем хранимых данных и ускорить вычисления. Особенно это важно в эпоху больших языковых моделей (LLM) и нейросетей, где вес модели может занимать сотни гигабайт и требовать серьёзных мощностей для работы. Для примера, известная открытая 27-миллиардная модель Gemma3 с квантованием весов до 4 бит (метод Q4 с осознанием квантования, Quantization Aware Training) успешно показывает результаты, сопоставимые или лучше, чем GPT-3.
5, при объеме менее 20 ГБ, что позволяет запускать модель на обычном оборудовании без серверов с терафлопсами вычислений.Квантование в нейросетях применяется в основном к весам, которые представляют собой параметры, отвечающие за работу моделей. В оригинальном состоянии веса представлены в виде чисел с плавающей точкой высокой точности, что отражает тонкие особенности обучения. Квантование разбивает эти значения на блоки и переводит их в целочисленные значения более низкой разрядности, применяя разные методы масштабирования и смещения для минимизации потерь.В llama.
cpp – популярной открытой библиотеке для локального запуска LLM – применяются три основных метода квантования. Вариант Type 0 (симметрический) делит веса на блоки, в каждом из которых вычисляется масштаб, чтобы представить значения на более низком уровне. Вариант Type 1 (асимметрический) дополнительно учитывает минимальное значение в блоке, чтобы скорректировать смещение и более точно восстановить данные. Более сложный метод K-quants группирует блоки в суперблоки и применяет к ним отдельные шкалы квантования, что позволяет добиться компромисса между точностью и размером модели. Этим методам посвящено сравнительно мало научных публикаций, однако практическая реализация показывает их эффективность.
Важно отметить, что ошибки, возникающие при квантовании, нельзя полностью исключить, но их влияние можно минимизировать. Простой подсчет разницы между исходными и квантованными весами мало что показывает для понимания качества модели. Гораздо информативнее смотреть на изменение выходных эффектов модели – например, через метрику перплексии, которая отражает степень уверенности модели в предсказанных результатах в сравнении с эталонным набором данных, таким как текст из Википедии. Анализируя разницу между логарифмами вероятностей предсказания правильного токена у исходной и квантованной модели, исследователи могут определить, как сильно квантование повлияло на качество работы.Опыт показывает, что при правильном подходе к квантованию модели в большинстве случаев сохраняют очень высокую точность, а возникающие ошибки проявляются как небольшой добавочный шум или искажения в выходных данных, схожие с эффектом снижения битовой глубины звука или цвета.
Другими словами, для конечного пользователя разница часто оказывается незаметной или несущественной, тогда как выгода от значительного уменьшения размера модели и ускорения работы очевидна.Следует подчеркнуть, что квантование – лишь один из элементов оптимизации моделей. В сочетании с техникой обучения с учетом квантования (QAT) оно позволяет моделям адаптироваться к условиям сжатия, снижая ошибку квантования непосредственно на этапе обучения. Благодаря этому современные LLM с небольшим объемом способны конкурировать с большими аналогами, значительно расширяя возможности широкого круга пользователей.Демонстрация квантования сопровождается интерактивными наглядными примерами, в которых можно увидеть и услышать, как меняется аудиосигнал при уменьшении битовой глубины, а также как ухудшается качество изображения при снижении числа цветов.
Это помогает глубже понять природу ошибки квантования и ее влияние в разных контекстах.Квантование продолжит играть ключевую роль в развитии технологий, делая сложные вычислительные задачи доступными на более скромном оборудовании. В то время как наука о квантовании постоянно развивается, применяются новые методы и улучшенные алгоритмы, исследователи и разработчики продолжают искать баланс между эффективностью, скоростью и качеством. В конечном итоге, именно осмысленное применение квантования позволяет достигать нового уровня производительности и экономии, особенно в сфере ИИ и обработки цифрового контента.Если у вас есть интерес к теме квантования, ошибки и оптимизации моделей, вы можете обратить внимание на реализацию в проектах типа llama.
cpp, а также на исследования в области QAT и K-quants. Это поможет лучше понять не только технические детали, но и практическое значение квантования, которое уже сегодня меняет подходы к созданию и использованию современных приложений.