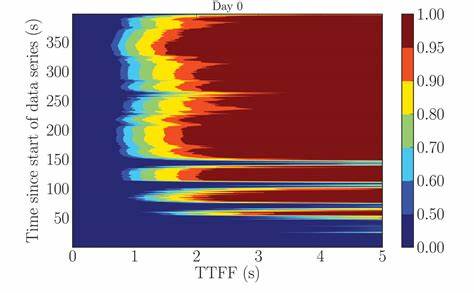
В условиях динамического развития информационных технологий и постоянного роста требований к качеству программного обеспечения, процессы непрерывной интеграции становятся краеугольным камнем эффективной разработки. Ключевым показателем в этих процессах является время до первого сбоя, или TTFF (Time to First Failure), отражающий скорость получения первым тестом информации о дефекте после внесения кода. Данный показатель напрямую влияет на производительность команды разработчиков и качество продукта в целом, так как позволяет оперативно выявлять ошибки и устранять их на ранних этапах циклов разработки. За последнее время компания OP Labs провела ряд изменений и оптимизаций в своих CI-процессах с целью сокращения TTFF. Проведенный анализ данных за три месяца нового 2024 года, основанный на использовании языкового инструмента R и библиотеки для статистической обработки и визуализации, позволил выявить как общие тенденции, так и характерные особенности поведения этого показателя в реальных условиях эксплуатации.
Важной частью анализа стала тщательная подготовка и очистка данных: исключение выходных дней и тех, где проведено менее пяти попыток запуска тестов, выявление и удаление аномальных значений, в частности негативных временных меток, что позволило получить максимально репрезентативное и достоверное представление о реальном состоянии процессов CI. Первичное исследование данных, включающее расчет основных статистических характеристик, показало значительное расхождение между показателями с учётом выбросов и без них. Среднее значение TTFF без учёта аномалий оказалось значительно ниже, что свидетельствует о влиянии редких, но существенно задерживающих процессов на общее восприятие производительности. Визуальный анализ распределения времени до первого сбоя через гистограммы и плотность вероятности подтвердил неоднородность и асимметричность данных. Наблюдалось смещение медианы и среднего, что характерно для данных с длинным «хвостом» — единичными задержками значительной продолжительности.
Изучение динамики TTFF в разрезе временных рядов выявило несколько ключевых дат и периодов, которые можно связать с изменениями в инфраструктуре или процессах. Выделение трендов с применением нелинейного сглаживания (loess) и линейного моделирования показало, что несмотря на начальное ухудшение показателя к концу июня и рост времени до первого сбоя, уже в конце июля наблюдается точка перелома, после которой начинается постепенное улучшение. Особое внимание уделялось сентябрю, когда благодаря внедрённым оптимизациям TTFF упал в среднем ниже одной минуты, что свидетельствует о значительном улучшении быстродействия CI-систем. Это удалось подтвердить и с помощью тестов на статистическую значимость, таких как Shapiro-Wilk для проверки нормальности и непараметрического теста Манна-Уитни для сравнения различных периодов. Результаты последних показали отсутствие нормального распределения данных, что объясняет выбор непараметрических методов анализа.
Значимые изменения в TTFF были выявлены при сравнении значений за сентябрь с предыдущими месяцами, а также с выделенными визуальными сегментами — ранним, средним и поздним периодами наблюдения. Наличие статистически значимых различий подтверждает влияние оптимизаций на процесс увеличения скорости обратной связи. В дополнение к тестам была проведена оценка эффективности изменений с использованием коэффициента эффекта Клиффа, который позволил количественно оценить масштабы различных промежутков времени. Полученные значения свидетельствовали о среднем эффекте, подтверждающем практическую значимость проведённых оптимизаций и их влияние на уменьшение времени до первого сбоя. Одним из трудностей анализа стала оценка влияния выбросов.
Их включение в данные изменяло результаты регрессионного анализа, приводя к тому, что без их исключения наблюдалось незначительное увеличение TTFF со временем. После исключения выбросов же была выявлена устойчиво снижающаяся тенденция, достигающая значимой статистической величины. Это подчёркивает необходимость тщательного мониторинга и управления аномалиями в процессе контроля качества. Регрессионный анализ, выполненный как в простой форме, так и с выделением сегментов тренда, указал на существование значимой точки перелома в середине августа 2024 года. До этой даты наблюдался рост TTFF, а после — чёткое снижение, что совпадает по времени с началом крупных оптимизационных мероприятий.
Различия в оценках этой точки между моделями с учётом и без учёта выбросов дополнительно подчёркивают важность корректного анализа данных и работы с аномальными значениями. Опыт OP Labs демонстрирует, насколько важно не только измерять ключевые метрики, но и регулярно применять продвинутые методы анализа для выявления тенденций и реакции на изменения. TTFF показал себя не просто числом, а эффективным индикатором, позволяющим оптимизировать процессы и улучшать скорость обратной связи, что в конечном счёте отражается на качестве выпускаемого программного обеспечения и удовлетворённости разработчиков. Таким образом, анализ времени до первого сбоя в CI-процессах открывает широкий простор для внедрения улучшений, направленных на снижение задержек в цикле разработки. Рекомендуется внедрять постоянный мониторинг TTFF с автоматизированной обработкой данных, что позволит своевременно выявлять срывы и устранять их причины.
Обращение отдельного внимания на выбросы и аномалии поможет сохранить устойчивость анализов и качество принимаемых решений. В перспективе стоит рассмотреть влияние дополнительных факторов, таких как рост сложности кода, изменения в инфраструктуре тестирования и использование новых технологий в CI/CD конвейерах. Интеграция комплексных аналитических инструментов поможет OP Labs и другим компаниям лучше адаптироваться к изменяющимся условиям и поддерживать высокий уровень эффективности разработки. Наконец, следует отметить, что успех в оптимизации TTFF является результатом не только технических улучшений, но и слаженной работы всей команды, владения инструментами статистики и аналитики, а также внимательного отношения к деталям в каждом элементе процессов непрерывной интеграции.