Retrieval-Augmented Generation (RAG) является одной из ведущих рамок для создания генеративных моделей искусственного интеллекта, способных отвечать на вопросы на основе частных и обширных наборов данных. Однако с постоянным ростом новых методов в этой области возникает насущная потребность в стандартизированном подходе к оценке их эффективности и точности. Именно для решения этой задачи была разработана BenchmarkQED - современный комплекс инструментов, предназначенный для автоматизации процесса бенчмаркинга RAG-систем, обеспечивающий воспроизводимость и масштабируемость оценивания. BenchmarkQED представляет собой многофункциональную платформу, которая включает в себя модули для автоматической генерации запросов, тщательной оценки качества ответов и подготовки датасетов для проведения тестов. Такой комплексный подход позволяет исследователям и разработчикам получать объективные и сопоставимые данные об эффективности своих моделей на различных наборах текстовой информации.
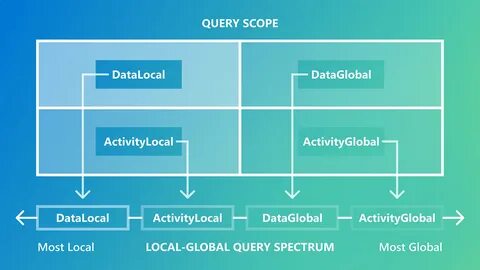
Основное преимущество BenchmarkQED заключается в ее способности поддерживать широкий спектр метрик качества и работать с разными типами вопросов и контекстов. Ключевой вызов, стоящий перед разработчиками RAG-систем, заключается в разнообразии запросов, которые модели должны обрабатывать. Эти запросы варьируются от локальных, подразумевающих поиск ответа в ограниченном числе текстовых фрагментов, до глобальных - требующих глубокого анализа больших массивов данных и синтеза информации, выходящей за пределы прямых соответствий. Традиционные векторные методы RAG хорошо справляются с локальными запросами, ориентированными на непосредственное сопоставление текста, но значительно теряют эффективность при необходимости обобщённого понимания и комплексного вывода интуитивно скрытых тем и связей. BenchmarkQED решает эту проблему благодаря интеграции с инновативной системой GraphRAG - расширением традиционных подходов, использующим большие языковые модели для создания и обобщения графов знаний на основе сущностей.
GraphRAG позволяет генерировать более развернутые и разнообразные ответы, способные охватывать широкий спектр глобальных вопросов, что открывает новые возможности для приложений, ориентированных на сложные аналитические задачи. Важным компонентом BenchmarkQED является AutoQ - метод автоматического синтеза запросов, адаптированный для всех типов задач от локальных до глобальных. AutoQ классифицирует запросы по четырём уникальным классам, формирующим структурированный спектр сложности и области применения. Этот инструмент позволяет автоматически создавать разнообразные запросы с возможностью точной настройки распределения и объёма, что способствует стандартизированному и эффективному тестированию без необходимости ручной настройки под каждый датасет. Процесс синтеза запросов в AutoQ опирается на глубокое понимание содержимого датасета и его тематической структуры, обеспечивая, что сгенерированные запросы релевантны и пригодны для всесторонней оценки моделей.
Это значительно повышает точность и объективность измерений, поскольку позволяет проверить, насколько хорошо система обрабатывает как простые, так и комплексные вопросы. Оценка качества ответов в BenchmarkQED осуществляется с помощью AutoE - автоматизированного блока, использующего метод "LLM-в-качестве-судьи". Этот подход включает представление пар ответов одной и той же задачи языковой модели для сравнения по заданным критериям, таким как полнота, разнообразие, релевантность и способность расширять знания пользователя. Путём множественных сравнений и агрегирования результатов формируется понятный индекс эффективности каждой модели на различных типах запросов. AutoE предоставляет возможность не только определять выигрыш одних моделей над другими, но и выявлять области, где ответы требуют улучшения.
Использование передовых моделей GPT-4 и GPT-4o для оценки гарантирует высокую достоверность и согласованность выводов, а также адаптивность к разным датасетам и задачам. Не менее важным элементом платформы является AutoD - компонент, предназначенный для автоматизированного отбора и структурирования данных. Поскольку текстовые датасеты существенно различаются по глубине, широте и связности тематических кластеров, AutoD обеспечивает выравнивание структурного профиля данных, что способствует проведению сопоставимых экспериментов на разных базах. Этот модуль формирует выборки с заданным числом тематических групп и соответствующим количеством примеров в каждой из них, позволяя получать сбалансированные и репрезентативные результаты. AutoD также поддерживает создание тематических резюме, которые не только служат вспомогательным инструментом при генерации запросов и оценке ответов, но и представляют ценность для других приложений, где важно компактно и ясно отображать содержание данных при ограниченном объёме контекста.
BenchmarkQED уже доказала свою эффективность в ряде сравнительных экспериментов с использованием различных конфигураций моделей и параметров. В частности, LazyGraphRAG - одна из основных разработок, использующих возможности GraphRAG в сочетании с эффективной стратегией запросов и генерации ответов - стабильно демонстрирует высокие показатели по всем основным метрикам качества. Эксперименты на датасетах новостей AP News и других показали, что LazyGraphRAG превосходит даже расширенные версии векторных RAG с огромным контекстным окном в 1 миллион токенов, подтверждая тем самым значимость продвинутого подхода к обработке глобальных вопросов. Еще одним важным аспектом BenchmarkQED является активное содействие развитию сообщества исследователей и практиков. Наборы данных, применяемые в экспериментах, такие как версии транскриптов подкаста Behind the Tech и статьи AP News, свободно доступны в репозитории BenchmarkQED на GitHub.
Это обеспечивает открытость и воспроизводимость исследований, а также стимулирует дальнейшие инновации в области RAG и вопросно-ответных систем. Современные применения Retrieval-Augmented Generation ориентируются на предоставление максимально информативных, точных и понятных ответов на вопросы пользователей, что особенно важно для работы с приватными и специализированными базами данных. BenchmarkQED, благодаря комплексному подходу к оценке, синтезу и подготовке данных, создает новые стандарты качества в этой сфере, ускоряя выработку лучших практик и совершенствование алгоритмов. Использование BenchmarkQED дает сильное конкурентное преимущество компаниям и исследовательским центрам, специализирующимся на разработке интеллектуальных систем поддержки принятия решений, корпоративных помощников и аналитических сервисов. Автоматизация процессов тестирования позволяет значительно снизить трудозатраты и повысить точность измерений, а гибкость инструментов обеспечивает адаптацию к разнообразным задачам и структурам данных.
Подытоживая, BenchmarkQED является важным шагом к объективному и системному исследованию возможностей Retrieval-Augmented Generation. Ее модули AutoQ, AutoE и AutoD формируют мощный инструментальный набор для всесторонней оценки систем, а интеграция с GraphRAG и LazyGraphRAG расширяет горизонты применения и потенциал генерации ответов. Продвижение этих разработок способствует не только развитию технологий на стыке обработки естественного языка и искусственного интеллекта, но и облегчению доступа пользователей к сложной информации, обогащая опыт взаимодействия с интеллектуальными системами будущего. Для тех, кто занимается разработкой и внедрением RAG-систем, BenchmarkQED предоставляет надежный фундамент для исследований, тестирования и сравнительных анализов. Рекомендуется ознакомиться с открытыми репозиториями и документацией на GitHub, а также следить за обновлениями и публикациями, регулярно выходящими от команды разработчиков Microsoft Research, чтобы использовать последние достижения в своих проектах и оставаться в авангарде отрасли.
.