В последние годы большие языковые модели (Large Language Models, LLMs) стали одной из главных тем в мире искусственного интеллекта и обработки естественного языка. Они лежат в основе таких приложений, как продвинутые чат-боты, ассистенты и генераторы текста, способные имитировать человеческую речь с поразительной точностью. Несмотря на их широкое применение, многие до сих пор не вполне понимают, как они работают изнутри. В этой статье мы подробно рассмотрим принципы работы LLM, объясняя ключевые процессы и связанные с ними математические операции, простым и понятным языком, подходящим для специалистов технического профиля без глубоких знаний в области ИИ. Большие языковые модели оперируют с текстом, представляемым в виде последовательности токенов - специальных кодов, соответствующих словам, частям слов или символам исходного текста.
Однако токены сами по себе не несут смысловой нагрузки и представлены просто набором чисел. Чтобы модель могла эффективно работать с такими данными, первый шаг - преобразование токенов в многомерные векторы, называемые эмбеддингами. Эти эмбеддинги - своего рода числовое представление смысла, которое связывает похожие слова и понятия, помогая модели понять контекст и взаимосвязи в тексте. Для выполнения этого преобразования в языке машин создаётся матрица эмбеддингов, где каждая строка соответствует отдельному токену, а столбцы - измерениям в эмбеддинг-пространстве. Когда поступает токен, модель извлекает из матрицы соответствующий вектор.
Такой метод позволяет превратить дискретные, не связанные между собой идентификаторы в среду с непрерывным значением, где близкие по смыслу слова находятся рядом. Следующий важный этап - добавление информации о позиции токенов в предложении. Модели вроде GPT-2 используют так называемые позиционные эмбеддинги, которые, аналогично токенам, имеют фиксированный размер и размерность, и добавляются к токенам поэлементно. Это позволяет трансформеру учитывать порядок слов, ведь сами по себе эмбеддинги токенов не отражают последовательность в тексте. Без этой информации модель не могла бы понять, находится ли слово в начале или конце предложения, что критично для правильного понимания контекста.
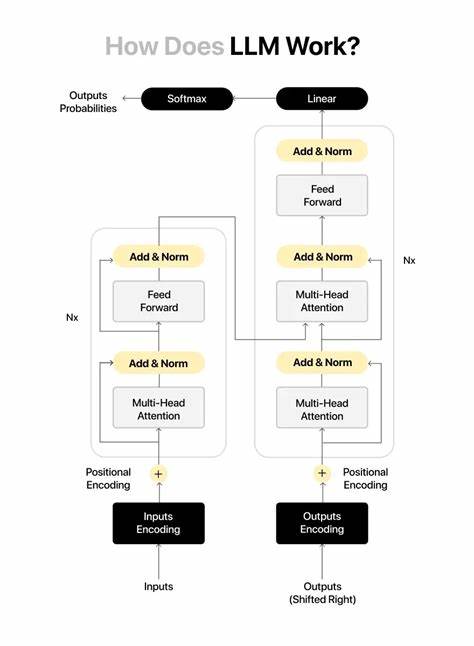
Центральным элементом архитектуры LLM являются трансформерные блоки - небольшие вычислительные модули, состоящие из подпроцессов, которые последовательно обрабатывают эмбеддинги, добавляя всё больше информации о контексте. Каждому входному эмбеддингу эти блоки добавляют новые "заметки", таким образом углубляя понимание модели о тексте. Количество таких слоёв и их параметры зависят от архитектуры, но например GPT-2 в базовой версии содержит 12 таких трансформерных блоков. Основным механизмом внутри трансформерного блока считается механизм внимания, в частности мультиголовное внимание. Его задача - позволить модели смотреть на предыдущие токены и выделять наиболее важные для текущего, обеспечивая тем самым контекстное обогащение.
На самом базовом уровне, в рамках одной "головы" внимания, происходит определённый вид сопоставления токенов. Каждый токен получает три новых представления: ключ (key), запрос (query) и значение (value). Они вычисляются путём умножения исходного эмбеддинга на проекционные матрицы, которые были обучены в процессе тренировки модели. Ключи и запросы находятся в одном низкопараметрическом пространстве, что позволяет вычислить степень соответствия или релевантности между токенами через скалярное произведение их векторов. Далее, матрица запросов перемножается с транспонированной матрицей ключей, чтобы получить матрицу скорингов внимания.
Каждая ячейка в этой матрице отражает, насколько сильно один токен должен обращать внимание на другой - чем выше значение, тем важнее токен для понимания текущего контекста. Чтобы избежать нарушения языкового порядка, применяется маска с отрицательной бесконечностью для "будущих" токенов, запрещая модели смотреть вперед, что имитирует естественный процесс понимания человеческой речи. После этого коэффициенты внимания нормализуются с помощью функции softmax, превращая их в вероятности, сумма которых равна единице. Эти вероятности используются для получения контекстных векторов путем взвешенного суммирования значений (value) всех токенов, что позволяет каждой позиции в последовательности иметь доступ к наиболее релевантной информации из всех предыдущих слов. Мультиголовное внимание представляет собой параллельное выполнение нескольких таких "голов" внимания, каждая из которых обучается фокусироваться на разных аспектах текста - синтаксических связях, лексических особенностях, или более сложных паттернах.
Итоговые контекстные векторы всех голов объединяются линейным преобразованием, возвращая размерность, совпадающую с размерами исходных эмбеддингов и позволяя следующему шагу трансформера эффективно с ними работать. После механизма внимания данные проходят через слой нормализации, а затем трансформерный блок применяет простую полносвязную нейросеть или feed-forward network. Эта сеть расширяет пространство векторов до более высокой размерности, обрабатывает результат через нелинейную функцию активации GELU (Gaussian Error Linear Unit) и сжимает обратно к исходному размеру, добавляя тем самым дополнительные вычислительные возможности для обработки сложных паттернов и зависимости в тексте. При этом важную роль играет механизм остаточных связей (residual connections). Он гарантирует, что исходная информация о токенах не будет потеряна при прохождении через слои трансформера и помогает избежать проблем с затуханием градиента при обучении больших моделей.
По сути, к выходу каждого основного блока прибавляется некий "шлейф" исходного входа, что улучшает стабильность и качество итогового представления текста. В конце всей цепочки трансформерных блоков получаются итоговые эмбеддинги, которые отражают глубокое понимание текста с учётом всего предшествующего контекста. Следующая задача - преобразовать эти эмбеддинги обратно в вероятностное распределение по словарю модели, чтобы определить, какой токен наиболее вероятно следует за данным отрезком текста. Для этого применяется операция проекции из эмбеддинг-пространства обратно в пространство словаря. Очень часто используют транспонированную матрицу исходных эмбеддингов - этот приём называется связыванием весов (weight tying), позволяя значительно сократить количество параметров модели без потери качества.
На выходе получается вектор логитов - чисел, соответствующих неотсортированной вероятности быть следующим словом для каждого токена в словаре. Их можно преобразовать в вероятности с помощью функции softmax, после чего выбирается наиболее вероятный следующий токен. Во время генерации текста модель последовательно получает на входе предыдущие токены и для каждого из них вычисляет вероятности следующего, что позволяет ей создавать грамматически правильные и семантически обоснованные предложения. Для повышения разнообразия или конкретных свойств построенного текста применяются дополнительные методы - температурное масштабирование, подции (top-k), или сэмплирование по вероятностям. Важно понимать, что параметров в современных больших языковых моделях может насчитываться сотни миллионов или даже миллиарды.
Все эти параметры - элементы матриц весов, включая эмбеддинги, проекционные матрицы внимания и веса нейросетей - обучаются на огромных массивах текстовых данных с помощью алгоритмов оптимизации, обычно стохастического градиентного спуска и его вариантов. Результатом является модель, которая способна захватывать сложные языковые зависимости и использовать их для генерации ответов или выполнения других задач. Таким образом, работа большой языковой модели - это сочетание преобразования дискретных токенов в непрерывные эмбеддинги, инжекции информации о позиции, последовательной обработки трансформерами с механизмами внимания, нормализацией, резидуальными соединениями и обратным проецированием в пространство словаря для создания прогнозов. Все эти процессы происходят благодаря большому количеству параллельных matrix-операций, которые воплощаются в эффективном программном и аппаратном обеспечении, что позволяет моделям работать быстро и производительно. Понимание принципов работы LLM помогает не только создавать более качественные приложения, но и глубже осмысливать потенциал и ограничения современных систем искусственного интеллекта.
Несмотря на кажущуюся сложность, архитектура LLM основана на тщательно продуманных и интерпретируемых математических механизмах, которые мы продолжаем изучать и совершенствовать. В итоге эти технологии открывают новые горизонты в обработке языка и взаимодействии человека с машиной. .