В современной программной инженерии сжатие данных продолжает оставаться востребованным и важным направлением. Среди множества алгоритмов сжатия BZip2 занимает особое место благодаря своей высокой степени сжатия и эффективности. Однако разработка конкурентного энкодера BZip2 с нуля — задача, которую многие считают непростой и требующей значительных усилий и времени. В 2024 году благодаря эволюции языковых средств и доступности новых инструментов такая задача стала реально выполнимой даже в ограниченные сроки. В этой статье речь пойдёт о том, как создать конкурентоспособный BZip2 энкодер на языке Ada всего за несколько дней, опираясь на современные возможности и лучшие практики.
Язык программирования Ada традиционно ассоциируется с надёжностью, детерминированностью и высокой безопасностью, что делает его привлекательным для системного программирования и задач, требующих максимального контроля над ресурсами и стабильностью. При этом Ada часто недооценивают в мире алгоритмов сжатия, где более популярны C, C++ и Python. Тем не менее, Ada благодаря своим мощным абстракциям и поддержке параллелизма может выступать эффективной средой для реализации сложных алгоритмов сжатия. BZip2 основан на комбинации нескольких алгоритмов: блоковой сортировке (Burrows-Wheeler transform), Move-to-front кодировании, хафмановском кодировании и специальных методах для обработки данных внутри блоков. Основная сложность при создании энкодера состоит в реализации всей цепочки преобразований так, чтобы итоговое сжатие было конкурентоспособным и скорость обработки не уступала существующим решениям.
При разработке с нуля важно изначально продумать архитектуру приложения. В случае BZip2 энкодера это означает создание модульной структуры, где каждый этап сжатия реализован как отдельный компонент. Это облегчает тестирование, отладку и дальнейшую оптимизацию. Ada предоставляет богатый инструментарий для модульности и контроля интерфейсов, что значительно упрощает реализацию сложной логики без утраты читаемости кода. Ключевым шагом является реализация Burrows-Wheeler transform (BWT), который меняет расположение символов таким образом, что последовательности одинаковых символов срастаются, повышая эффективность последующего сжатия.
При этом важна оптимизация по времени и памяти, поскольку BWT является ресурсозатратным процессом. В Ada возможно эффективно использовать массивы и записи с контролем времени жизни объектов, что позволяет эффективно управлять ресурсами при этом алгоритме. Следующий этап — Move-to-front (MTF) кодирование. В отличие от BWT, MTF кодирование работает с индексами символов, заменяя символы на их позиции в списке, который обновляется с каждой итерацией. Реализация этого алгоритма на Ada позволяет использовать типы данных с гарантированной безопасностью и встроенные механизмы исключений, что способствует созданию более надёжного и простого в сопровождении кода.
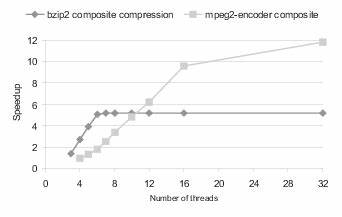
Для дальнейшего сжатия данных применяется адаптивное Хаффмановское кодирование, где символы кодируются с использованием переменной длины, оптимизированной под частоты их появления. Ada предлагает возможности для эффективной работы с битовыми операциями, что важно при реализации хаффмановских деревьев и кодирований, поскольку точность и скорость битовых манипуляций влияют напрямую на производительность и степень сжатия. Одной из сложностей при создании энкодера с высокой производительностью является оптимизация работы с памятью и параллелизация вычислений. Современный Ada поддерживает многопоточность и задачи (tasking), что позволяет реализовать параллельную обработку блоков данных без значительных дополнительных затрат на синхронизацию. Такой подход особенно полезен в современных многоядерных системах и позволяет достичь уровня эффективности, сопоставимого с решениями на более популярных языках.
Немаловажным аспектом является тестирование и верификация корректности алгоритма. Ada исторически позиционируется как язык для создания ответственного софта, где ошибки могут дорого стоить. Использование встроенных возможностей контрактных программ, предусловий и постусловий, а также строгой типизации помогает свести к минимуму количество ошибок и сделать программу более предсказуемой. Практический совет разработчикам, которые планируют реализовать энкодер BZip2 на Ada, состоит в тщательном планировании и формулировании минимально необходимого набора функций, который позволит достичь приемлемых показателей сжатия и скорости в короткие сроки. Начать стоит с базовой реализации BWT и MTF, затем постепенно добавлять усложняющиеся компоненты, уделяя особое внимание профилированию и оптимизации критических участков кода.
Важно отметить, что создание конкурентного энкодера BZip2 полностью с нуля за несколько дней возможно благодаря современным компиляторам Ada, которые обеспечивают высокий уровень оптимизации, а также благодаря развитому сообществу и доступности библиотек для работы с битовыми потоками и структурами данных. Современные IDE и инструменты анализа кода делают процесс разработки более быстрым и качественным. В заключение стоит подчеркнуть, что Ada, несмотря на свою не столь широкую популярность в нише алгоритмов сжатия, обладает всеми необходимыми характеристиками для создания высококачественного и эффективного BZip2 энкодера. Современные возможности языка, многопоточность, строгость и безопасность кода способствуют быстрой и надёжной реализации сложных алгоритмов. Разработка подобного проекта за несколько дней демонстрирует, что грамотный подход и правильное использование инструментов могут значительно ускорить процесс создания сложного программного обеспечения и привести к конкурентоспособным результатам на уровне лучших решений.
Опыт создания собственного BZip2 энкодера на Ada не только расширяет знания о самом языке, но и погружает в тонкости алгоритмов сжатия, что открывает новые горизонты для программистов, желающих вывести свои навыки на новый уровень современного системного программирования.




![The Most Beautiful Program Ever Written [video]](/images/3C5DD8EB-1B8E-465A-A22D-404A544D735B)

