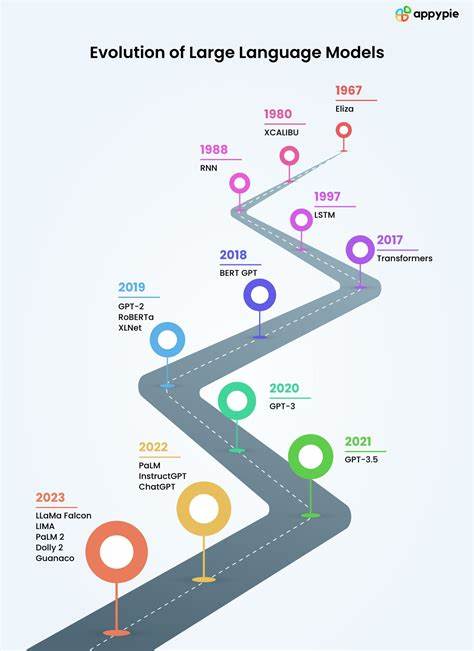
Языковые модели сыграли ключевую роль в развитии искусственного интеллекта и обработки естественного языка. Их создание и совершенствование стали частью большого научного путешествия, начавшегося задолго до появления современных мощных инструментов вроде GPT-4.5. История развития языковых моделей отражает амбиции человечества научить машину говорить, понимать и взаимодействовать с окружающим миром на уровне, близком к человеческому. Зарождение идей о языковых моделях можно проследить до середины XX века.
В 1949 году Алан Тьюринг представил концепцию теста Тьюринга, который призван измерить способность машины использовать язык таким образом, чтобы человек не мог отличить её от живого собеседника. Это стало отправной точкой для разработки алгоритмов и моделей, способных понимать и генерировать текст. Несмотря на эти задатки, создание эффективных языковых моделей оказалось сложной задачей — к примеру, Элайза, созданная в 1966 году, хоть и стала известной программой для имитации диалога, так и не прошла критерии теста Тьюринга. Одна из первых практических технологий, применяемых для моделирования языка, основывалась на цепях Маркова. Клод Шеннон в своей работе 1949 года продемонстрировал, как можно использовать цепи Маркова для приближенного предсказания последовательностей символов.
Принцип цепей Маркова состоит в описании вероятностного перехода от одного состояния к другому, что в случае текста позволяет прогнозировать следующий символ или слово, основываясь на предыдущих. Однако у цепей Маркова были и существенные ограничения. Простые модели, рассматривающие лишь один предыдущий символ, выдавали бессмысленный текст. Для улучшения качества можно было увеличить размер контекста, то есть опираться сразу на несколько предшествующих элементов, но это требовало экспоненциально большего объёма памяти для хранения всех вероятностных переходов. Кроме того, при увеличении контекста выходная последовательность всё больше походила на заученный текст, теряя способности к генерации оригинального содержания.
Другим важным шагом в развитии языковых моделей стал переход от работы с отдельными символами или полностью готовыми словами к использованию промежуточных единиц — токенов. Применение токенизации позволило сделать модели более гибкими и эффективными. Так, метод байтового попарного слияния (Byte Pair Encoding, BPE) стал заметным прорывом в разделении текста на подсловные единицы, которые лежат между символами и словами по уровню подробности. BPE работает по принципу последовательного объединения наиболее часто встречающихся пар символов или уже сформированных токенов в более крупные единицы. Это позволяет модели не заучивать просто конкретные слова, а разбирать язык на части, которые могут встречаться в разных словах и комбинациях.
Благодаря этому языковые модели, работающие с BPE, приобретают способность понимать и создавать новые слова, что значительно повышает качество генерации текста и уменьшает вероятность порождения бессмыслицы. Современные крупные языковые модели (Large Language Models, LLM), такие как GPT, работают именно с токенами, используя мощные архитектуры, основанные на трансформерах. Инновационной идеей трансформера является механизм самовнимания (self-attention), который позволяет модели динамически присваивать разный вес словам в контексте при генерации следующего токена. Благодаря этому модель способна учитывать сложные зависимости и структуру текста, что делает выходные данные более связными и осмысленными. GPT (Generative Pre-trained Transformer) получила название благодаря сочетанию предварительного обучения на огромных корпусах текстов и способности самостоятельно генерировать связный текст по полученному контексту.
Первые версии GPT продемонстрировали высокую эффективность на задачах генерации, перевода и понимания языка, а последующие итерации существенно улучшили качество и масштаб обучения. Одной из ярких демонстраций успешности современных языковых моделей стало успешное прохождение теста Тьюринга в контролируемых условиях. Так, по последним данным, GPT-4.5 смогла обмануть 73% судей, которые приняли её за человека. Этот результат стал символом достижения спустя почти восемь десятилетий с момента старта исследований в области машинного понимания языка.
Текущее состояние технологий базируется на глубоком понимании статистических закономерностей и сложных алгоритмах, позволяющих моделям не просто машинально повторять паттерны данных, но и создавать уникальные тексты, обладающие логикой и даже творческим потенциалом. Это открывает новые возможности для автоматизации, генерации контента и общения с компьютерами на естественном языке. Несмотря на впечатляющие успехи, языковые модели всё ещё остаются предметом активных исследований. Направления развития связаны с созданием более эффективных алгоритмов, оптимизацией объёмов обучающих данных и улучшением интерпретируемости моделей. Также изучается, как сделать ИИ более этичным и безопасным при взаимодействии с пользователями.
Подводя итог, можно сказать, что история языковых моделей — это история постепенного и последовательного достижения цели научить машины понимать и использовать язык. От простых цепей Маркова через инновационные методы токенизации и самовнимания трансформеров — все эти этапы в совокупности сформировали современные инструменты, задающие тон в области искусственного интеллекта и цифровой коммуникации.