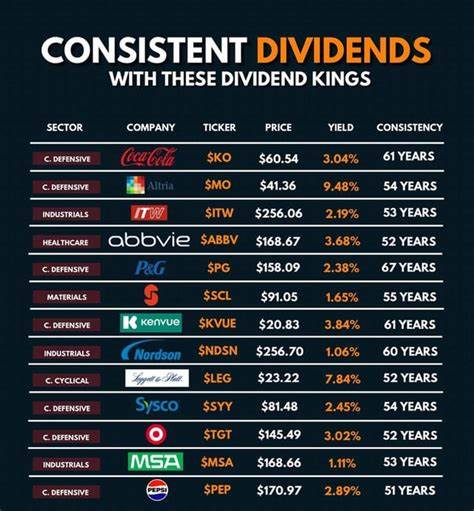
Современные искусственные интеллект-системы, особенно языковые модели, во многом зависят от качества и объема данных, на которых они обучаются. Тренировка таких моделей требует миллиардов и триллионов токенов информации, которые должны быть не просто большим потоком текста, а структурированными и помеченными с учетом тематики, сложности контента и других важных параметров. В этом контексте появление Essential-Web v1.0 представляет собой значительный прорыв и новый этап в развитии обучающих датасетов для ИИ. Essential-Web v1.
0 — это огромный набор данных, состоящий из 24 триллионов токенов, собранных из разнообразных интернет-источников, тщательно отобранных и структурированных для максимальной пользы в задачах машинного обучения. Отличительной особенностью этого датасета является то, что каждый документ в нем снабжен подробной двенадцатикатегорийной таксономией, охватывающей такие аспекты, как тема, формат, сложность контента и качество. Таксономия и аннотация данных — ключевые факторы в повышении эффективности обучения языковых моделей. Они позволяют оптимально фильтровать и выбирать данные для конкретных целей, будь то научные исследования, программирование, медицина или гуманитарные дисциплины. Для создания таких меток в Essential-Web v1.
0 использована модель EAI-Distill-0.5b — тонко настроенная нейросеть с 0.5 миллиардами параметров, которая демонстрирует точность разметки, сопоставимую с одной из самых крупных современных моделей Qwen2.5-32B-Instruct, уступая ей всего около 3%. Это обеспечивает высокое качество аннотаций и делает выборку данных максимально релевантной и полезной.
Набор данных Essential-Web v1.0 открывает новые возможности для исследователей и разработчиков, предлагая гибкие SQL-подобные фильтры, с помощью которых можно быстро формировать специализированные поднаборы. Такие фильтры позволяют создавать датасеты, ориентированные на отдельные направления, например, математика, программирование, STEM-наука или медицина. При этом качество и полнота подобных выборок остаются на уровне, близком к современным эталонным наборам данных: для математических данных показатель всего на 8% ниже лучших известных результатов, для веб-кода качество на 14% выше, а выборки по STEM и медицинским темам демонстрируют улучшение на 24,5% и 8,6% соответственно. Данная работа получила поддержку от Simons Foundation и ряда ведущих образовательных и исследовательских институтов, что подчеркивает её важность и значимость для академического и индустриального сообществ.
Публикация артикля и самого датасета на открытой платформе HuggingFace гарантирует широкий и удобный доступ для всех заинтересованных пользователей, способствуя дальнейшему развитию и внедрению лучших практик в области искусственного интеллекта. Значение Essential-Web v1.0 выходит далеко за рамки простого объема текста. Она представляет собой инструмент нового поколения, который позволяет сэкономить значительные ресурсы времени и вычислительной мощности при подготовке тренировочных наборов. К тому же тщательная разметка таксономией делает процесс обучения моделей более прозрачным и управляемым, что особенно важно для создания систем, которые должны работать в специализированных и требовательных к качеству областях.
Одним из вызовов при работе с такими объемными и разнообразными наборами данных остается обеспечение их актуальности и регулярного обновления. В мире веб-контента информация быстро устаревает, появляются новые темы, форматы представления данных и лингвистические особенности. Essential-Web v1.0 — это базовая версия, но её авторы планируют дальнейшую работу по улучшению, расширению и поддержанию качества данных, что будет учитывать не только количественные, но и новые качественные характеристики информации. Сравнивая Essential-Web v1.
0 с другими известными наборами данных, стоит отметить, что многие из них либо меньше по объему, либо не обеспечивают столь богатой аннотации. Отсутствие детальной таксономии в других датасетах приводит к необходимости сложной дополнительной фильтрации и дополнительной предобработки, что существенно замедляет процессы обучения современных ИИ-моделей. Essential-Web решает эту проблему изначально, выступая как универсальная платформа для создания узкоспециализированных и высококачественных наборов данных. Выбирая Essential-Web v1.0, специалисты получают превосходный инструмент для решения широкого круга задач: от разработки новых языковых моделей, способных понимать сложный технический текст, до создания систем автоматического анализа медицинских данных и помощи в научных исследованиях.
Фокус на качество и структурированность контента позволяет максимально быстро добиться высоких результатов, оптимизируя процесс обучения и оценивания моделей. Таким образом Essential-Web v1.0 формирует новые стандарты для индустрии обработки естественного языка и машинного обучения. Его значимость становится очевидной в эпоху, когда данные — это главная валюта для интеллектуальных систем, а их грамотная подготовка и организация — ключ к инновационным прорывам. Эта инициатива не только ускоряет развитие ИИ технологий, но и делает их более доступными, надежными и разнообразными.
Для исследователей и разработчиков, планирующих применять искусственный интеллект в своих проектах, Essential-Web v1.0 несет в себе потенциал улучшения качества конечных продуктов и сокращения времени на разработку. Использование такого мощного и структурированного ресурса позволяет глубже понять сложные взаимосвязи между различными категориями и типами данных, а также открывает новые горизонты для создания более продвинутых и устойчивых моделей. С ростом рынка искусственного интеллекта и усилением конкуренции, доступ к большим и качественным ресурсам становится необходимостью. Essential-Web v1.
0 — это инновация, которая помогает удовлетворить эту потребность, предоставляя комплексный и структурированный датасет мирового уровня. Его появление знаменует собой новый этап в истории развития ИИ, открывая путь к более сложным, точным и адаптивным системам в будущем.