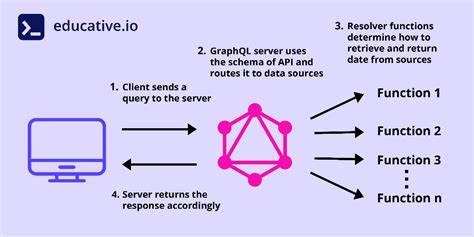
GraphQL за последние годы занял прочное место в арсенале современных разработчиков, предлагая удобный и мощный способ взаимодействия между клиентскими приложениями и серверами. На первый взгляд, технология кажется революционной: она заявляет о сильной типизации, декларативном подходе к извлечению данных и возможности клиента самостоятельно указывать, какие именно сведения ему необходимы. Однако за этими привлекательными характеристиками скрывается множество нюансов и ограничений, которые часто остаются незамеченными до того момента, когда начинаешь серьезно работать с GraphQL в масштабных и разнообразных проектах. Важно понимать, что многие из достоинств GraphQL сопровождаются своеобразными «звездочками» — особенными условиями и сложностями в имплементации, которые влияют на пользовательский опыт, производительность и масштабируемость сервисов. В основе GraphQL лежит принцип, согласно которому запрос формируется в строгом соответствии с потребностями клиента.
Это значит, что фронтенд указывает, какие именно поля и связи ему необходимы, и получает от сервера именно такую выборку. Кажется, что это решает вечную проблему избыточного или недостаточного извлечения данных, которая часто встречается в REST API. Но на практике без тщательной организации схемы, грамотного описания типов и применения инструментов, таких как GraphQL Code Generator или gql.tada, риск получить неидеальное взаимодействие все еще достаточно велик. Все преимущества сильной типизации достигаются лишь тогда, когда разработки сопровождаются полноценным автогенерированием типов и поддержкой LSP (Language Server Protocol), что накладывает дополнительные требования на инструментальную базу и дисциплину команды.
Одним из часто восхваляемых свойств GraphQL является способность к само-документированию API. При условии, что разработчики тратят время на тщательное описание входных параметров и возвращаемых типов, это действительно облегчает понимание и ускоряет процесс разработки. Однако это также ведет к дополнительным временным затратам и часто становится точкой трения, когда поддержка схемы и документации начинает отставать от реальной разработки. Еще одна сложность заключается в том, что базовый подход GraphQL к запросам не подразумевает фрагментного колокационного паттерна, из-за чего часто приходится возвращаться к корневому запросу, чтобы добавить необходимые поля. Отсутствие в языке примитивов, позволяющих легко решать эту проблему, приводит к дополнительным головным болям и усложняет организацию кода.
Значительной проблемой в GraphQL называют и версионирование API. В сообществе часто подчеркивается идея отказа от версий, предлагая взаимодействовать с версионностью посредством поддержания устаревших полей бесконечно долго. Это может работать для внутреннего использования, но становится крайне проблематичным для публичных API, где структура продукта и бизнес-логика со временем неизбежно меняются. Реальность такова, что поддержка версии API — необходимый процесс, позволяющий делать радикальные изменения без риска сломать совместимость с уже существующими клиентами. Еще одна заметная оговорка связана с тем, что стандартный GraphQL работает через единый endpoint.
Хотя это звучит как преимущество с точки зрения унификации, на практике подобное решение создает сложности с мониторингом и трассировкой запросов. В итоге появляются рекомендации по использованию Persisted Operations — заранее скомпилированных операций с уникальными идентификаторами, которые значительно упрощают работу в продакшен-среде и облегчают аналитику. При отсутствии таких механизмов разработчики сталкиваются с недостаточной производительностью и сложностями с кешированием, ведь стандартный метод отправки POST-запросов не позволяет полноценно использовать HTTP-стандарты, что является потерей для производительности и безопасности. Отметим, что несмотря на все недостатки, по мнению многих разработчиков, GraphQL действительно облегчает работу в мультиклиентских проектах, где требуется обслуживать мобильные приложения, веб-клиенты и другие интерфейсы одновременно. Возможность декларативно указывать нужные данные и получать гарантированно соответствующий типам результат является сильным конкурентным преимуществом.
Однако реальность работы с GraphQL требует привлечения мощных инструментов, таких как Relay или GraphQLSP, которые частично нивелируют проблемы отсутствия развитого LSP-тулчейна и сложности с организацией операций в большом масштабе. В последние годы популярность GraphQL несколько затмевают альтернативные подходы, среди которых выделяются REST, tRPC и серверно-ориентированные UI-подходы. Традиционный REST, несмотря на объявленную «древность», остается мощным и простым инструментом, особенно для публичных API. REST предполагает возврат ресурсов без вложенных связей, что при правильной организации позволяет гибко версионировать API с помощью URL и легко управлять кешем на уровне HTTP. Несмотря на то, что типизация в REST-сервисах требует дополнительных усилий и часто реализуется через OpenAPI спецификации, она остается более доступной и прогнозируемой, чем хитросплетения GraphQL типов.
REST подходит для систем, ориентированных на управление отдельными ресурсами, такими как CMS, и остается более понятным решением для начинающих пользователей или внешних клиентов. Сравнивая с tRPC, стоит отметить, что этот инструмент привлекает разработчиков своей типобезопасностью и простотой настройки, объединяя сервер и клиент в одном TypeScript-мире с единой типовой системой. Это избавляет от ряда сложностей, присущих GraphQL, и позволяет быстрее стартовать проекты благодаря четко заданным рекомендациям и опиниям. Однако tRPC предполагает использование TypeScript на обеих сторонах и лучше всего подходит для проектов с ограниченным числом клиентов и монорепозиториями. Интроспективность, документация и масштабируемость тянут на себя меньше внимания в tRPC, что создаёт компромиссы, особенно в крупных и распределенных командах.
Менее распространенный, но выигрышный с точки зрения прототипирования подход — серверно-ориентированный UI, с его ядром в React Server Components. Его суть в том, что сервер возвращает не данные, а описание интерфейса, которое клиент переводит в элементы UI. Это позволяет в определенной степени сократить разрыв между представлением и данными, а также создавать адаптивные решения для разных платформ на единой кодовой базе. Однако эта методология очень тесно связана с React и требует от разработчиков владения полным стеком, что скорее ограничивает ее применение, нежели расширяет. Все рассмотренные технологии служат хорошим напоминанием о том, что в мире программирования совершенства не существует и каждый инструмент — лишь компромисс между удобством, масштабируемостью, производительностью и простотой поддержки.
GraphQL — сложный, мощный и перспективный инструмент, но чтобы раскрыть его потенциал, требуется не только правильный выбор инструментов и подходов, но и вклад сообщества в развитие экосистемы. Авторы и поддерживающие GraphQL надеются, что новые инициативы — такие, как интеграция Persisted Operations, создание удобных типов и улучшенная документация — помогут избавиться от ключевых недостатков и позволят технологии занять ещё более важное место в индустрии. В конечном итоге выбор между GraphQL, REST, tRPC или серверно-ориентированным UI зависит от конкретных нужд проекта, состава команды и требований к масштабированию. Важно своевременно осознавать ограничения и особенности каждого решения, чтобы избежать ловушек, которые создают многочисленные «звездочки» рядом с заманчивыми преимуществами. Зрелость и успех любой технологии определяются не идеальной концепцией, а практическими результатами и удовлетворенностью как разработчиков, так и конечных пользователей.
Глядя в будущее, можно предположить, что GraphQL продолжит эволюционировать, становясь более дружелюбным к новичкам и масштабируемым в больших проектах. Сегодня же вызов состоит в том, чтобы признать его ограничения, активно развивать инструменты, способные нивелировать эти сложности, и распространять лучшие практики среди сообщества разработчиков. Лишь совместными усилиями возможно превратить GraphQL из спорной и многогранной технологии в надежный и эффективный стандарт для построения API следующего поколения.