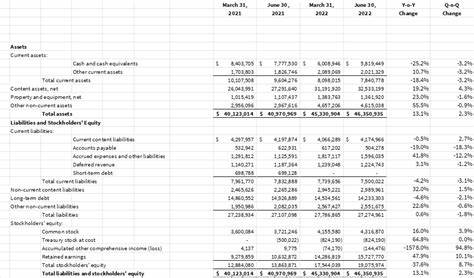
С развитием технологий искусственного интеллекта и появлением крупных языковых моделей (LLM) возникает всё более острый спрос на эффективные и масштабируемые решения для инференса с низкой задержкой. Такие приложения, как генеративный ИИ, требуют не только высокой производительности, но и гибкости в управлении ресурсами, особенно в многозадачных и распределённых вычислительных средах. Традиционные системы инференса зачастую не способны удовлетворить эти требования, что стимулирует разработку новых технологий для оптимизации производительности и распределения нагрузки. Одним из прорывных решений в области инференса является Nvidia Dynamo — открытая и независимая от конкретного движка платформа, предназначенная для обеспечения низкой задержки и высокой пропускной способности при работе с крупными моделями. Dynamo поддерживает разнообразные среды выполнения, такие как TRT-LLM, vLLM и SGLang, что позволяет интегрировать его в существующие стеки ИИ без значительных затрат на миграцию.
Принципиально важной особенностью Nvidia Dynamo является разделение вычислений на два основных этапа: фазу предварительного заполнения (prefill) и фазу декодирования (decode). В LLM инференсе эти шаги отличаются по характеру нагрузки: prefill выполняется параллельно по токенам, а decode — автогрессивно, формируя каждый последующий токен на основе ранее сгенерированных. Традиционные архитектуры зачастую выполняют эти задачи на одних и тех же GPU, вызывая конкурентность ресурсов и ухудшая производительность. Dynamo же разъединяет эти фазы по разным узлам или GPU, позволяя оптимизировать параметры параллелизма и масштабирование для каждой из них. Такое раздельное управление ресурсами особенно полезно для рабочих нагрузок с длительными входными последовательностями и относительно короткими ответами, либо наоборот.
Например, в сценариях Retrieval Augmented Generation (RAG) длинные входы обрабатываются отдельным пулом prefill-нод, что освобождает decode-узлы для скорого ответа пользователям. Управление таким масштабированием и распределением ресурсов осуществляется с помощью компонента Dynamo Planner, который динамически мониторит метрики системы, включая скорость запросов, длину последовательностей, загрузку GPU и времена ожидания в очередях. Dynamo Planner способен адаптировать количество рабочих процессов под каждую фазу, двигаясь между агрегированным и разделённым режимами выполнения в зависимости от нагрузки. Такая адаптивность позволяет эффективно использовать вычислительные ресурсы в реальном времени, обеспечивая соответствие целевым показателям качества обслуживания (SLO), таким как время до появления первой токены и задержка между токенами. Улучшения в маршрутизации запросов достигаются через Dynamo Smart Router — интеллектуальный компонент, который сокращает избыточные вычисления путём минимизации пересчёта KV-кэша (ключ-значение), что крайне важно для многоузловых разнесённых систем.
Smart Router отслеживает кешированные блоки на различных узлах и направляет запросы на те узлы, где уже присутствуют необходимая информация, что особенно эффективно в сценариях с частыми повторными запросами или диалогами с сохранением контекста. Управление KV-кэшем является одной из ключевых проблем в эксплуатации LLM-инференса, так как быстро растущий объём данных требует значительных ресурсов дорогостоящей GPU-памяти. Nvidia Dynamo решает эту проблему с помощью KV Cache Block Manager, который реализует ступенчатое хранение. Менее используемые или устаревшие блоки KV-кэша автоматически перемещаются из высокоскоростной GPU-памяти в более дешёвые и ёмкие слои, такие как оперативная память CPU, локальные SSD-диски или даже сетевые хранилища вроде Amazon S3. Для обеспечения высокой скорости передачи данных между памятью и узлами используется специализированная библиотека Nvidia NIXL.
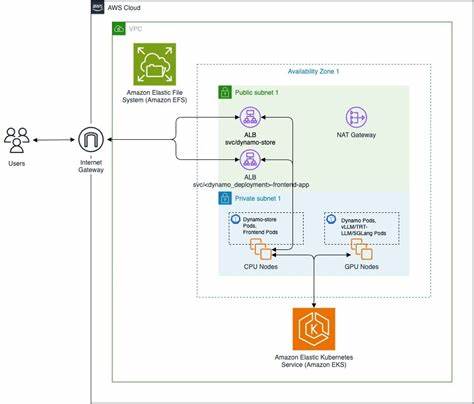
Она абстрагирует аппаратные и протокольные особенности, поддерживая GPUDirect Storage, UCX и интеграцию с S3, автоматически выбирая наиболее эффективный маршрут передачи. Такая архитектура помогает минимизировать задержку и повышает общую пропускную способность инференса. Для развёртывания и управления масштабируемыми многонодными кластерами для генеративного ИИ Nvidia Dynamo интегрируется с Amazon Elastic Kubernetes Service (EKS), что обеспечивает управление жизненным циклом контейнеров и автоматическое масштабирование вычислительных ресурсов. Amazon EKS изначально оптимизирован под использование GPU-ускорителей различных поколений — G6, P5, P6 и другие — с предустановленными драйверами и необходимым софтом. Особое внимание уделено повышению производительности сетевых соединений через AWS Elastic Fabric Adapter (EFA), обеспечивая низкую задержку и высокую пропускную способность при межузловых коммуникациях.
Важным элементом масштабируемой системы является автоматическое масштабирование с помощью решений типа Karpenter, позволяющего динамически поднимать новые GPU-инстансы по мере возрастания нагрузки и быстро их выключать, когда они становятся лишними. Это значительно оптимизирует затраты и повышает эффективность использования облачных ресурсов. Для хранения больших моделей и их весов применяется интеграция с такими решениями, как Amazon Elastic File System (EFS), Amazon FSx для Lustre и OpenZFS, а также с объектным хранилищем Amazon S3. Это позволяет обеспечить высокоскоростной доступ к данным для всех узлов кластера и гибко выбирать нужный вариант хранения в зависимости от рабочих сценариев. Развёртывание решения включает в себя клонирование репозитория, выполнение инфраструктурной автоматизации с помощью скриптов Terraform и Helm, настройку операторов Kubernetes, установка необходимого программного обеспечения и библиотек.
После запуска системы можно тестировать работу моделей через сетевые интерфейсы, обращаясь к API и проверяя метрики через Prometheus и панель Grafana, которые поставляются как часть набора инструментов мониторинга. Эксплуатация системы включает ведение журналов, мониторинг показателей производительности, управление безопасностью с помощью AWS Identity and Access Management (IAM) и настройку сетевых изоляций через виртуальные частные облака (VPC). Это позволяет создавать надежные и защищённые решения, удовлетворяющие требованиям коммерческого применения. В заключение, использование Nvidia Dynamo совместно с Amazon EKS предоставляет производителям и разработчикам искусственного интеллекта мощные инструменты для ускорения и масштабирования генеративных моделей. Открытая архитектура, модульный дизайн и глубокая интеграция с облачными сервисами AWS делают это решение гибким и экономичным.