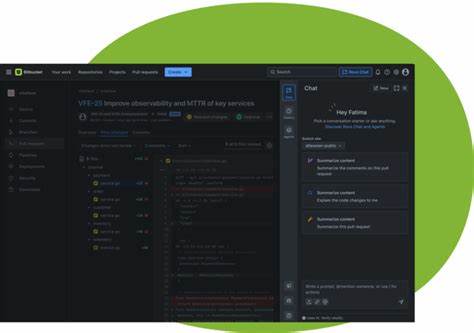
Поиск кода - одна из фундаментальных задач для разработчиков, которые ежедневно работают с большими объемами исходного кода. Несмотря на кажущуюся простоту задачи, чем больше и сложнее проект, тем более критичны становятся задержки и производительность поисковых систем, используемых в работе. В Graphite Chat перед нами встала задача создать инструмент для поиска по коду, способный работать с сотнями тысяч и даже миллионами файлов на любом коммите, а не только в дефолтной ветке, что значительно усложняет реализацию и выдвигает высокие требования к инфраструктуре. Классические решения, основанные на grep и аналогичных утилитах, а также существующие API поисковых сервисов оказались недостаточно гибкими для наших нужд. Рассмотрим подробнее, почему традиционный подход не работает, какие технологии мы тестировали, и как в итоге пришли к уникальному и высокопроизводительному решению, подходящему для масштабных проектов и актуальных задач разработчиков.
Задача поиска кода в больших репозиториях сталкивается с несколькими ключевыми ограничениями. Во-первых, классические инструменты поиска, например grep или более продвинутые ripgrep, требуют, чтобы файлы находились на достаточно быстром дисковом хранилище. Ещё одно важное условие - сравнительно небольшой размер кода, так как скорость поиска напрямую зависит от количества одновременно сканируемых файлов. В нашем случае поддержка репозиториев, имеющих сотни тысяч файлов, а также возможность поиска по любым коммитам, а не только по основной ветке, требовала переосмысления подходов. Именно эти моменты поставили перед нами проблему, которую нельзя было решить привычными методами без значительных потерь в производительности.
Известные сервисы для поиска кода, такие как GitHub и Sourcegraph, имеют ограничения, главным из которых является фокусирование на дефолтной ветке репозитория. Они либо вовсе не индексируют остальные ветки, либо учитывают их только в отдельных случаях. Такой подход оправдан с точки зрения экономии ресурсов и оптимизации работы в основном сценарии, но в условиях Graphite Chat это стало препятствием. В отличие от них, нам требовалась поддержка поиска в абсолютно любой ветке и на любом этапе разработки, что усиливало нагрузку и требования к системе. На практике это означало невозможность полагаться на готовые решения или API, ведь их архитектура изначально не предполагала такой функциональности.
В поисках решения мы сначала обратились к простейшему варианту - git grep. Предполагалось, что использование стандартного инструмента даст нам быстрый и надежный результат без необходимости внедрения сложных систем. Однако эксперименты с разными типами хранилищ в экосистеме AWS - от EFS до EBS и с разными моделями обработки запросов - показали: несмотря на локальные преимущества каждого варианта с точки зрения ввода-вывода, все они не могут быстро обрабатывать репозитории большого масштаба из-за ограничений, связанных с кешированием на уровне операционной системы. Другими словами, ускорить выполнение запроса можно было либо повторным использованием данных из кеша, либо ожидать значительного замедления при первом поиске. Такая ситуация не устраивала, так как пользователи хотят выдать результат практически мгновенно вне зависимости от того, сколько и каких коммитов они ищут.
Переход на индексирование стоял на повестке дня, поскольку поиск по проиндексированным данным может сократить время обработки запроса до миллисекунд. Для проверки мы попробовали Elasticsearch - одну из наиболее популярных и эффективных платформ для полнотекстового поиска. Тесты продемонстрировали, что эта система справляется с запросами за очень короткое время даже на больших объемах данных. Однако проблема масштабируемости возникла вновь, когда пришлось учитывать хранение индексов для тысяч репозиториев, каждый из которых содержит сотни тысяч файлов и тысячи коммитов. Индексация каждого состояния каждого коммита привела бы к взрыву объема данных и затрат на инфраструктуру, а это не вписывалось в бюджет и не было практически реализуемо.
В поисках оптимального решения мы обратились к основам Git, чтобы понять, как он сам хранит такие большие объемы репозиториев с длинной историей и множеством коммитов, не занимая при этом терабайты дискового пространства. Важная идея Git состоит в хранении в виде объектов двух типов: blobs и trees. Blobs - это содержимое отдельных файлов, а trees - структуры, описывающие совокупность blob-ов, которые относятся к определенному коммиту или дереву файлов. Благодаря этому Git эффективно управляет версиями, избегая дублирования данных и экономя место. Используя этот подход, мы построили собственную систему индексирования, имитирующую логику Git.
Вместо хранения простого набора документов, как это делается в классических индексах, мы стали сохранять вместе с blob-ами и отдельные tree-объекты, соответствующие коммитам. При поиске выполняется параллельный запрос на получение списка файлов (trees) для нужного коммита и поиск в blob-ах, соответствующих поисковому запросу. После этого результаты фильтруются в памяти, чтобы оставить только те файлы, которые содержатся в рамках запрошенного дерева. Благодаря последовательной и параллельной архитектуре обработки достигается высокая скорость и точность результатов. Эффективность данного метода объясняется тем, что большинство файлов в репозитории изменяются редко, и общее количество уникальных версий каждого файла невелико по сравнению с общим числом файлов.
Это позволяет индексу оставаться компактным и выполнять поиск без необходимости полного перебора всех историй. Также мы оптимизировали фильтрацию как потоковую операцию, способную сразу отдавать клиенту первые результаты, не дожидаясь окончания всего процесса поиска. Сегодня наша система работает в продакшене, обслуживая тысячи запросов с задержкой менее миллисекунды, что значительно превосходит результаты, которые можно было получить с помощью API GitHub или классических grep. Мы проиндексировали десятки миллионов исходных файлов, охватывающих тысячи репозиториев, и это позволило нам вывести на новый уровень UX в Graphite Chat, сделав работу с кодом быстрее и удобнее. Переосмысление подхода к поиску и использование внутренних механизмов Git помогло избежать масштабных проблем с хранением и производительностью, при этом сохранив гибкость и возможности поиска среди алгоритмически сложных данных.
В планах у нас дальнейшее улучшение модели индексирования, внедрение оптимизаций, направленных на уменьшение размера tree-объектов, а также расширение функционала за счет интеграции с нейросетевыми технологиями и семантическим поиском, который позволит находить не просто совпадения строк, а контекстно релевантные результаты. Разработка и внедрение такого решения потребовали глубокого анализа, экспериментов и терпения, но результат подтвердил, что инновации в области хранения и обработки кода экранно влияют на эффективность и удобство работы разработчиков. Graphite Chat сегодня демонстрирует, что правильный подход к архитектуре индексирования и поисковым механизмам способен сделать интерактивный поиск по коду быстрым и масштабируемым, открывая путь для создания новых инструментов, которые помогут командам создавать программное обеспечение быстрее и качественнее. .




![Univers Freebox :: Voir le sujet - [Résolu]Disques durs Freebox Delta](/images/38A16EB3-95C9-43AD-BB93-62B7E5453DBA)