Архитектура Zen 5 от AMD является одним из самых значимых обновлений в серии процессоров Ryzen, демонстрируя множество технических новшеств и улучшений по сравнению с предыдущим поколением Zen 4. Несмотря на то, что Zen 5 заметно превосходит Zen 4 в синтетических тестах и задачах продуктивности, впечатления от игрового опыта при использовании не-X3D вариантов Zen 5 оказались неоднозначными. Рассмотрим детально, как процессор Ryzen 9 9900X с ядрами Zen 5 справляется с игровыми нагрузками и какие факторы влияют на итоговую производительность в популярных современных играх. Техническое совершенство и архитектурные нововведения Zen 5 включают увеличение ёмкости переупорядочивания команд и переработку исполнительного движка, что делает процессор шире и глубже по сравнению с Zen 4. Эти изменения обеспечивают улучшенную работу при выполнении высокопроизводительных вычислений и многозадачности.
Тем не менее, в играх наблюдается, что прирост производительности не столь заметен, что связано с особенностями программных нагрузок и архитектурными ограничениями. Для тестирования использовался процессор Ryzen 9 9900X с оперативной памятью DDR5-5600, а видеокартой NVIDIA Radeon RX 9070. Тесты проводились на играх Palworld, Call of Duty Cold War и Cyberpunk 2077. При этом нужно учитывать, что игровой опыт сравнивался с предыдущими испытаниями на ядрах Lion Cove, где поменялись настройки и версии игр, что ухудшает возможность прямого сопоставления результатов. Главной целью стало выявление общих закономерностей в поведении процессора Zen 5 под игровой нагрузкой.
Анализ производительности начался с исследования узких мест в работе конвейера процессора на этапе переименования и выделения ресурсов (rename/allocate). Эта стадия часто оказывается узким местом из-за ограничений пропускной способности, и потеря инструкций именно здесь снижает загрузку всех остальных частей ядра. Если в Lion Cove был ощутимый эффект от задержек памяти на заднем плане, то в Zen 5 проблема сместилась: процессор сильнее страдает из-за латентности на фронтенде — участке, ответственном за предварительную обработку и подачу инструкций. Фронтенд Zen 5 содержит продвинутый механизм, включая большой кеш операций размером 6 тысяч записей и стандартный кеш инструкций L1i объёмом 32 килобайта. Используется раздельный предсказатель ветвлений с огромным буфером трассировки ветвлений (BTB) на 24 тысячи записей.
Такая конфигурация позволяет покрывать большую часть исполняемого потока инструкций посредством кеша операций, существенно повышая скорость обработки. Однако, несмотря на улучшенную способность кеша операций по сравнению с Lion Cove (6K против 5.2K), в играх наблюдается более высокий уровень промахов в L1i, что может влиять на задержки и снижать общую эффективность работы. Интересен факт, что точность предсказателя ветвлений в играх оказалась чуть ниже, чем у Lion Cove, несмотря на преимущества Zen 5 в сложных тестах SPEC CPU2017. Это непривычное явление, возможно, связано с особенностями игровых сцен и динамикой инструкций.
Промахи предсказания ветвлений приводят к дорогостоящим перенаправлениям конвейера, увеличивая фронтенд-задержки и вызывая дополнительную работу процессора по отмене неправильных инструкций — признак ухудшения пропускной способности и использования ресурсов. Zen 5 также имеет разделённый BTB, где первый уровень содержит 16 тысяч, а второй — 8 тысяч записей. Переход к более глубокой записи второго уровня BTB замедляет предсказание, хотя и помогает покрыть большую область ветвлений. Это создает дополнительные задержки в предсказательном процессе, которые, хотя и частично скрываются за счет работы конвейера, в целом ограничивают скорость фронтенда. Отметим, что декодеры инструкций работают с пропускной способностью менее 4 микрокоманд за такт и задействованы лишь в небольшом количестве циклов, что свидетельствует о том, что увеличение ширины декодера, скорее всего, даст лишь минимальный прирост скорости.
Что касается задержек в стадии переименования, то обычно фронтенд-задержки длятся около 11-12 тактов, что близко к задержкам кеша L2. Таким образом, фронтенд часто ожидает загрузки инструкций из более медленных уровней памяти. Пропускная способность кеша операций при этом значительно ниже максимума — около 6 микрокоманд в такт из 12 возможных, хотя для полной загрузки ядра нужен уровень около 8 микрокоманд. Основной сдерживающий фактор здесь — частота появления ветвлений в потоке инструкций, которые мешают расширенному и непрерывному извлечению команд из кеша операций. В работе задней части ядра (бэкенда) ограничения возникают из-за заполнения ресурсов, таких как регистр общего назначения, буфер переупорядочивания (ROB) и различные очереди.
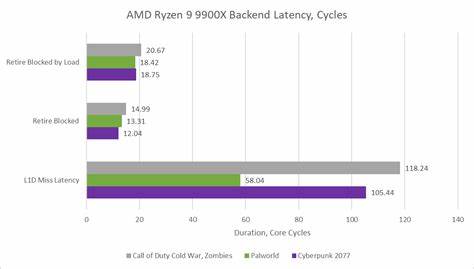
Zen 5, благодаря реорганизации, получил достаточно большие унифицированные планировщики и улучшенную организацию работы с плавающей запятой, что значительно снижает вероятность узких мест на этом уровне. Процессор способен держать в полёте до 448 инструкций, что позволяет скрывать задержки при ожидании данных из памяти. Тем не менее, задержки доступа к памяти остаются серьезной проблемой. Часто стадия завершения инструкций (retirement) блокируется из-за незавершенных загрузок, которые могут длиться до 18-20 тактов. Локальный кеш данных первого уровня (L1d) демонстрирует длительность промахов, сопоставимую с предыдущими поколениями Zen.
Особенности груза памяти в разных играх приводят к различиям в средней латентности кэша L1d, причём в играх Call of Duty Cold War и Cyberpunk 2077 задержки заметно выше, чем в Palworld, где, наоборот, наблюдается большое количество кеш-промахов, но их подавление обеспечивается L2. Сравнение с архитектурой Intel существенно осложнено различиями в методах подсчёта статистики загрузок. Тем не менее аналитика указывает на преимущество Intel за счет наличия промежуточного уровня кеша L1.5d размером 192 КБ, который эффективно обслуживает часть запросов, снижая общую латентность. У AMD в свою очередь меньший L2 (1 МБ против 3 МБ у Intel) работает с меньшей задержкой, компенсируя ликвидность доступа к данным.
В то же время у Zen 5 и сохраняется сравнительно высокая доля обращений к кешу L3, в среднем около 55-68% в зависимости от игры. Большинство промахов в L3 ведет к обращениям в оперативную память, что существенно тормозит выполнение игр. Удалённые обращения в других CCD (кластеры ядер — CCX) оказываются довольно редким явлением и не вносят значимого вклада в общую задержку. При нагрузке ОС как правило старается оптимизировать работу, концентрируя потоки игры внутри одного CCX, где наблюдается максимум частотой и минимальными задержками, что уменьшает межкластерные обращения. Искусственное распределение игрового процесса по двум CCX приводит к падению производительности примерно на 7%, поскольку происходит увеличение количества обращений между CCX, где передача данных значительно медленнее из-за архитектурных особенностей.
Итоговая производительность игр на Zen 5 определяется как низким уровнем инструкций на такт (IPC) в игровых нагрузках, так и задержками фронтенда. Игры характеризуются плохой локальностью данных и команд, что затрудняет эффективное использование широкого и глубокого ядра. В условиях таких пород нагрузки выигрыши от увеличенного числа исполнительных единиц ядра и его ширина оказываются ограниченными, поскольку недостаточно насыщенных высокопроизводительных последовательностей инструкций, чтобы раскрыть потенциал архитектуры. AMD и Intel сталкиваются с похожими проблемами, но в разных частях процессорного конвейера — у Intel чаще возникают проблемы с задержками в бэкенде, а AMD более подвержена проблемам фронтенда. Такое разделение задач на оптимизацию архитектуры влияет на направления разработки.
Современный тренд ориентирован на увеличение максимальной производительности в сценариях с высоким IPC, в то время как низко IPC-ные случаи, характерные для игр, по-прежнему вызывают трудности и требуют новых решений. Перспективы дальнейшего улучшения игровых показателей лежат в области оптимизации кеш-подсистем и снижения задержек фронтенда. Комбинация элементов архитектуры Intel и AMD, например, у Intel есть большой и быстрый L1i кеш, а у AMD — низкая латентность кешей L2 и L3, теоретически могла бы дать заметный прирост. Также важным направлением станет уменьшение латентности и увеличение пропускной способности межкластерных коммуникаций, особенно в системах с большим количеством ядер. Помимо технических аспектов, стоит обсудить влияние системной топологии — разбиение больших процессорных комплексных устройств на CCD и CCX — на масштабируемость и производительность в многопоточных играх.
Несмотря на опасения, что высокое количество ядер и кластеризация приводят к падению производительности из-за разросшейся латентности межкластерных обращений, на практике современные системы оптимизируют работу таким образом, что большая часть игрового кода обрабатывается в пределах одного CCX, минимизируя издержки. В перспективе ожидается, что разработчики архитектур продолжат балансировать между увеличением пиковой производительности и поддержанием высокого уровня эффективности при низком IPC. Также возможен сдвиг внимания с узко тематических оптимизаций на очень сложные сценарии, допускающие лишь небольшие улучшения, но при этом востребованные повседневными нагрузками, такими как игры, офисные приложения, моделирование и дата-центр. Рассмотрение опыта работы AMD Zen 5 с современными играми и техническая детализация выявляют, что улучшения архитектуры существенны, но не всегда способны проявиться в условиях игровых нагрузок из-за характеристик софта и внутренней логики процессора. Эти наблюдения служат ориентиром для будущих поколений, таких как Zen 6 и последующие, где возможно будут реализованы решения для устранения текущих узких мест, улучшения кеш-подсистем, предсказателей и коммуникаций между ядрами.
Игровая отрасль продолжит оказывать значительное влияние на эволюцию процессорной архитектуры, требуя от производителей сбалансированного подхода, учитывающего сложность современных игровых движков и разнообразие нагрузок. Zen 5 является важным этапом в развитии AMD и иллюстрирует, что игровые задачи отличаются от синтетических бенчмарков и продуктивных кейсов, задавая свои уникальные требования к дизайну CPU.