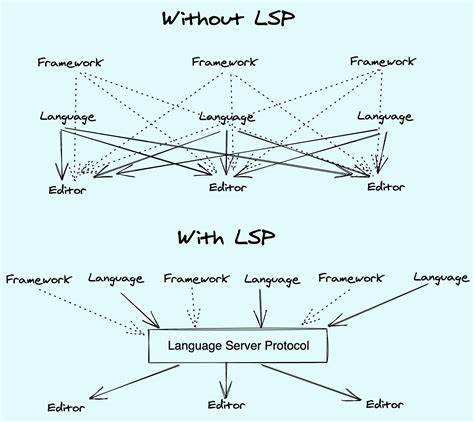
Языковой сервер – одна из центральных технологий, которая сегодня активно используется в разработке программного обеспечения. Эта технология позволяет редакторам кода и интегрированным средам разработки (IDE) предоставить разработчикам мощные инструменты, такие как интеллектуальная подсказка, переход к определению, диагностика кода и многие другие функции. Создание собственного языкового сервера – задача сложная, но чрезвычайно полезная, особенно если вы работаете с уникальным или малоизвестным языком программирования. В данной статье мы рассмотрим азы реализации языкового сервера, опираясь на протокол Language Server Protocol (LSP), а также поделимся практическими советами и обходными путями, которые помогут упростить этот процесс. Языковой сервер – что это и зачем он нужен Языковой сервер выступает посредником между редактором кода и языковыми инструментами, таким как компилятор, парсер или анализатор.
Основная задача сервера – принимать запросы от редактора (например, показать подсказки автозаполнения, найти определения или выделить синтаксические ошибки), обрабатывать их и возвращать результат в формате, понятном клиенту. Благодаря этому можно расширять редактор, не погружаясь глубоко в специфику конкретного языка, а опираясь на единый протокол взаимодействия. Language Server Protocol был разработан Microsoft и стал де-факто стандартом для реализации таких серверов. Он описывает структуру сообщений между сервером и клиентом на основе JSON-RPC, позволяя работать с разными языками и редакторами единым способом. Однако несмотря на простоту самого протокола, реализация полноценного сервера вызывает ряд технических вызовов, о которых важно знать заранее.
Основы протокола и его особенности LSP использует простой протокол общения, который условно можно сравнить с HTTP, но без методов. Каждое сообщение состоит из обязательных заголовков и тела, причем важнейшим заголовком является Content-Length, определяющий размер JSON-сообщения. Транспорт для передачи тела сообщения может быть самый разный: стандартный ввод/вывод (stdio), сокеты или именованные каналы (pipes). На практике большинство популярных серверов, например clangd, используют stdio из-за его универсальности и легкости в настройке. Тем не менее канал stdio накладывает определенные ограничения.
Логи от сервера выводятся в стандартный поток ошибок (stderr), который, будучи дочерним процессом, сложно отследить в редакторе. В дополнение, отладка сервера осложнена тем, что процесс запускается динамически, и его PID каждый раз уникален. Чтобы решить эти проблемы, рекомендуется использовать отдельные текстовые редакторы или реализовать прокси-сервер, который выступает посредником между клиентом и языковым сервером через сокеты, позволяя удобно просматривать логи и подключать отладчики. Инициализация сервера и завершение сеанса Коммуникация начинается с обязательного сообщения initialize от клиента, в котором происходит согласование возможностей сервера и клиента. Сервер должен корректно ответить и дождаться уведомления initialized, прежде чем обрабатывать другие сообщения.
Такой фиксированный процесс упрощает синхронизацию и позволяет определить, что сервер полностью готов к обслуживанию запросов. Завершение работы тоже структурировано: клиент посылает shutdown-запрос, получая ответ, после чего отправляет exit-уведомление. Это разграничение помогает серверу понять, что соединение закрывается намеренно, а не из-за ошибки передачи или аварийного завершения. Синхронизация документа – фундаментальный элемент Ключевым функционалом языка является оперативное отражение изменений в редактируемых файлах. Поскольку редактор работает с копиями документов, а не напрямую с файлами на диске, важной задачей языкового сервера становится управление кэшированием измененного содержимого.
Клиент отправляет уведомления textDocument/didOpen для открытия документа, textDocument/didChange – для обновления и textDocument/didClose – для его закрытия. Все эти уведомления должны отражаться в локальной структуре данных сервера, обеспечивая консистентность и возможность полноценного анализа. Одним из простых способов реализации в начале является стратегия полной замены содержимого документа при каждом изменении (TextDocumentSyncKind.Full), при которой клиент посылает весь текст. Такая методика не является оптимальной с точки зрения производительности, но значительно облегчает этап начальной реализации и отладки.
Идентификация документов базируется на URI, но поскольку некоторые языки или системы не используют URI напрямую, можно применять относительные пути от корневой директории проекта, получаемой из сообщения initialize. Важно выбирать однозначный способ идентификации для избежания конфликтов. Диагностика в реальном времени Одна из главных причин, по которым разработчики хотят иметь языковой сервер – мгновенная диагностика ошибок и предупреждений в коде. После получения актуальной версии документа сервер вызывает парсер или компилятор для анализа и отправляет данные о найденных проблемах клиенту. Следует помнить, что при отсутствии ошибок необходимо отправлять пустые диагностические сообщения для очистки ошибок, которые могли быть обнаружены на предыдущих итерациях.
Также стоит учитывать управляющую логику, которая отслеживает измененные и посещенные файлы в проекте. Позиционное кодирование – важный технический нюанс LSP использует позиционное обозначение строк и столбцов в UTF-16 единицах, что связано с особенностями движка редактора VSCode, написанного на TypeScript. Для большинства языков и парсеров, оперирующих UTF-8, необходимо реализовать преобразование позиций между UTF-8 и UTF-16. Это может быть непростой задачей, требующей использования готовых библиотек для конвертации, например, utf8proc. Оптимально кэшировать разделение текста на строки, чтобы быстро рассчитывать позиции и ограничить накладные расходы при работе с документом.
Виртуальная файловая система как связующее звено Чтобы реализовать интеграцию с языковым сервером, полезно создать абстрактный слой файловой системы, который умеет работать как с дисковыми файлами, так и с содержимым, находящимся в памяти редактора. Такая виртуальная файловая система позволит избегать проблем с несинхронизированностью состояния и обеспечит корректное взаимодействие с системами импорта или включения модулей. Структурированная отчетность об ошибках Современные языковые бэкенды направляют ошибки и предупреждения в структурированном формате. Это особенно важно для передачи информации о точных позициях ошибок, связанных регионах и дополнительных условиях. В каждом случае желательно поддерживать API для подключения слушателей, принимающих детализированные сведения об ошибках вместо простого вывода строк в stderr.
Граф зависимостей и его роль Поддержка модульности и импортов в языке требует построения графа зависимостей между файлами или модулями проекта. Такой граф помогает эффективно обновлять результаты анализа при изменениях в отдельных частях проекта, избегая полной переработки всего кода. Он используется для каскадного распространения изменений, оптимизации времени отклика и обеспечения правильного контекста для функций "перейти к определению" и "найти все ссылки". Обработка множественных уведомлений и дебаунсинг Редакторы часто посылают серию быстрых сообщений с изменениями в одном файле. Запуск анализа после каждого сообщения приведет к значительной нагрузке.
Чтобы снизить индексируемую нагрузку, рекомендуется реализовать задержку между получением изменений и запуском анализа, позволяя дождаться стабилизации текста. Символьный список – навигация в проекте Поддержка запросов документных и рабочих символьных списков расширяет удобство разработчика. Для реализации необходимо собрать информацию обо всех символах, определенных в файлах, а также уметь фильтровать их по подстроке или другим критериям. Для маленьких проектов обычно хватает прохода по всем известным модулям, тогда как в больших системах улучшение производительности достигается индексацией и кэшированием. Часто языковые компиляторы не предоставляют исходные средства для извлечения информации о символах, поэтому требуется написание специализированных модулей или генерация отладочной информации для получения соответствующих данных.
Переход к определению и поиск ссылок Фундаментальная функция для быстрой навигации по коду достигается путем сопоставления символов с их определениями и ссылками. Для эффективной работы генерируется граф ссылок на основе анализа проекта, связывающий каждый объект с его определением. Реализация включает обработку входящих запросов типа textDocument/definition и textDocument/references, преобразование координат позиции курсора в формат LSP и поиск соответствующих узлов в структуре данных. Локальный поиск обычно достаточно быстр при использовании оптимальных структур хранения. Для повышения скорости отклика можно заранее кэшировать позиции всех символов в формате UTF-16, что избавит от повторного пересчета при каждом запросе.
Особенности подсказок при наведении Использование функции hover позволяет показывать дополнительную информацию об элементе кода при наведении курсора. Эта возможность базируется на данных о символах и диапазонах, полученных при анализе проекта. Важно обеспечить поддержку параметра hoverProvider в возможностях сервера, чтобы клиент знал о доступности функции. Автодополнение – вершина языкового сервера Самая сложная, но и наиболее динамичная функция – систематическое автодополнение. Она реагирует как на специальные символы, заданные в triggerCharacters, так и на пользовательский вызов.
Для реализации необходимо на основании позиции курсора определить текущий токен, контекст его использования, сведения о видимых символах с учетом областей видимости и правил теней, а также построить список подходящих вариантов, учитывая префиксы и окружение. Важен точный разбор частично написанного токена, а также сохранение устойчивости даже при наличии синтаксических ошибок. Распределение предложений рекомендуется производить с указанием textEdit, а не только label, что позволяет клиенту корректно заменить или дополнить текущий участок кода, снижая неоднозначности. Рекомендуется продумать способ группировки символов для снижения перегруженности списков, например, объединять все символы из namespace в один элемент с указанием количества. Обработка ошибок и устойчивость к некорректному коду В процессе редактирования код часто бывает синтаксически некорректным, что может привести к провалам анализа и потере данных для автодополнения или диагностики.
Одним из практичных решений является хранение двух версий графов зависимостей и ссылок – "текущей" и "предыдущей". В случае обнаружения ошибок сохраняются символы из предыдущей версии для участков кода, следующих за ошибкой. Это снижает шум и улучшает пользовательский опыт, позволяя продолжать получать подсказки и навигацию даже в промежуточных состояниях. Заключение Создание языкового сервера – задача многогранная, требующая комплексного подхода к протоколам связи, внутренней структуре данных и взаимодействию с языковым бэкендом. При этом разработчики могут выбирать уровень сложности и полноту функционала, начиная с базовой синхронизации документов и заканчивая продвинутым автодополнением и навигацией по проекту.
Применение методик и паттернов, таких как виртуальная файловая система, структурированная отчетность, дебаунсинг и кэширование, значительно упрощает разработку. В итоге даже индивидуальные и нишевые языки программирования могут получить удобные инструменты, повышающие продуктивность их использования. Понимание и реализация Language Server Protocol открывает двери к развитию мощных расширений для популярных редакторов, помогая создать современную и комфортную среду для любого разработчика.