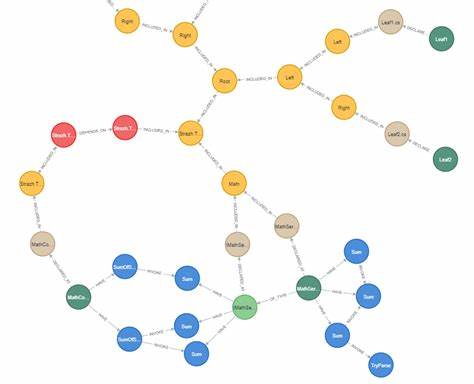
В современном программировании чрезвычайно важно иметь глубокое понимание структуры и взаимосвязей внутри кодовой базы. Особенно это касается крупных проектов, которые охватывают сразу несколько языков программирования и разнообразные модули. Классические методы чтения исходного кода, ручного анализа и документации уже не справляются с возросшими объемами и сложностью проектов. На этом фоне графовый подход к пониманию кодовой базы становится настоящим прорывом в области разработки и сопровождения ПО. Графовое представление кода основано на использовании структуры знаний, в которой узлы описывают ключевые компоненты кода — функции, классы, модули, пакеты, а ребра отражают связи и зависимости между ними — вызовы функций, наследование, импорты и прочее.
Такое представление не только визуально облегчает восприятие, но и позволяет проводить глубокий анализ посредством запросов к графовой базе данных. В результате разработчики могут задавать сложные вопросы о проекте на естественном языке и получать точные ответы с привязкой к исходному коду. Современные системы графового анализа кода активно используют парсинг исходного кода с помощью универсальной технологии Tree-sitter, которая поддерживает широкий спектр языков программирования. Это дает возможность анализировать как Python, JavaScript, TypeScript, C++, Rust, Lua, Java, так и актуальные в разработке Go, Scala и C#. Tree-sitter обеспечивает детальный абстрактный синтаксический анализ (AST), который необходим для построения качественной и точной модели кода.
Значительным преимуществом таких систем является хранение знаний о проекте в графовой базе данных Memgraph. База специализирована на эффективной работе с графовыми структурами, что позволяет быстро отвечать на сложные запросы и обеспечивает удобство масштабирования для супермасштабных репозиториев с тысячами файлов и миллионов линий кода. Возможность визуализации графов и их экспорта для дальнейшего анализа добавляет гибкости в интеграции с разработческими процессами и системами управления проектами. Поисковые возможности на естественном языке приводят к настоящей революции в работе с кодом. Разработчики могут задать вопросы вроде «Покажи все классы, содержащие 'User' в имени» или «Найди функции, связанные с операциями базы данных», не вспоминая специфические конструкции запросов к базе или названия файлов.
Искусственный интеллект автоматически переводит такие вопросы в Cypher — язык запросов для графовых баз данных, после чего результаты выводятся с фрагментами кода, что значительно ускоряет процессы понимания и разработки. Интеграция с мощными языковыми моделями, включая облачные решения Google Gemini и OpenAI, а также локальные AI-модели Ollama, расширяет возможности интеллектуального анализа и оптимизации кода. Автоматическое создание запросов к графовой базе, анализ паттернов кода и предложения по оптимизации на основе лучших практик превращают рутинную работу в интерактивный, разумный процесс, где разработчик сотрудничает с AI-ассистентом. Особая ценность представленного подхода — это возможность не только понимать код, но и безопасно его модифицировать. Аст-ориентированное точечное редактирование позволяет вносить изменения в определенные функции, методы или классы, не затрагивая весь файл.
Перед внесением изменений система предлагает визуально сравнить отличия, обеспечивая контроль и предотвращая ошибки. Такая многоязыковая поддержка охватывает все ключевые языки и востребованные возможности: Python с декораторами и вложенными функциями, современные возможности JavaScript и TypeScript, продвинутые фичи C++20, Rust с trait-ами, Java c generics и аннотациями. Отдельный модуль посвящен AI-оптимизации кода. Система анализирует структуру проекта, выявляет анти-паттерны и узкие места, а затем предлагает рекомендации с интерактивным запросом подтверждения от разработчика. Поддержка пользовательских эталонных документов и стандартов кодирования позволяет настроить процесс так, чтобы улучшения соответствовали корпоративным требованиям и архитектурным решениям.
Экспорт и интеграция с другими инструментами — еще одно важное преимущество. JSON-формат экспорта знаний позволяет создавать собственные скрипты анализа, системы генерации документации и любые другие решения, которые нуждаются в доступе к структурированным данным о проекте. Это повышает гибкость и расширяет горизонты использования графового анализа в самых разных областях. Для разработчиков и компаний, желающих расширить функционал, предусмотрена система добавления новых языков программирования. Используя инструментарий, основанный на Tree-sitter, можно быстро интегрировать поддержку уникальных языков и фреймворков, что особенно важно для гетерогенных или экспериментальных проектов.
Установка и настройка таких систем достаточно формализованы. Использование Python 3.12+, Docker, cmake и менеджера пакетов uv обеспечивает совместимость и удобное управление зависимостями. Конфигурация через .env-файлы позволяет легко переключаться между облачными и локальными AI-моделями, а также настраивать параметры подключения к Memgraph и пути к репозиториям.
Графовый анализ кода — это не просто инструмент для программиста, а целая среда для интеллектуальной работы с кодовой базой, ускоряющая обучение новых сотрудников, помогающая поддерживать высокое качество продукта, выявлять зависимости, находить ошибки и быстро вносить изменения. С ростом масштабов проектов такие технологии становятся ключевыми для эффективной разработки и поддержки ПО любого уровня сложности. В эпоху, когда цифровая трансформация стала двигателем прогресса, обладающие возможностями глубокого анализа и модификации кода решения играют важнейшую роль. Интеллектуальные RAG-системы на основе графов — это не будущее, а реальность сегодняшнего дня, которая открывает новые горизонты для разработчиков и компаний по всему миру.