PostgreSQL – одна из самых популярных и мощных систем управления базами данных, которая славится своей надежностью, гибкостью и широкими возможностями настройки. Одной из важнейших частей PostgreSQL является его система выполнения SQL-запросов, а именно процессы оптимизации и построения плана выполнения запроса. Понимание внутренней структуры плана выполнения запросов позволяет разработчикам глубже контролировать процесс работы базы, проводить тонкие настройки и даже создавать собственные инструменты мониторинга и анализа. Что такое план выполнения запроса в PostgreSQL? План выполнения — это структурированное, оптимизированное представление SQL-запроса, которое формируется системой после этапов парсинга и оптимизации. По сути, это дерево операторов, отражающих последовательность выполнения запроса: какие таблицы и как будут просматриваться, какие фильтры применятся, каким образом будут объединяться данные и так далее.
Уже на этапе планирования выполняется анализ статистики, оценка вариантов доступа к данным (индексы, последовательное сканирование), определяется, какие операции будут наиболее эффективны для конкретного набора условий. По сравнению с исходным текстом SQL запрос в плане превращается в объектно-ориентированное представление с узлами (Node), где каждый элемент соответствует определенному этапу обработки данных. Именно план выполнения определяет быстродействие запроса, поэтому его мониторинг и анализ — ключевые задачи DBA и разработчиков. Возможности перехвата и анализа плана запроса в PostgreSQL Интересная особенность PostgreSQL – возможность внедрять собственные хуки в слой исполнения запросов. Это дает уникальную возможность не только получить доступ к построенному плану, но и вмешиваться в процесс выполнения, изменять поведение, даже подменять результаты.
Такая функциональность открывает дорогу к созданию сложных решений обработки данных, кастомной оптимизации, трансляции запросов для векторных вычислений и анализа плана в режиме реального времени. Для работы с хуками необходимо собрать и установить отладочную версию PostgreSQL с поддержкой необходимых флагов и опций. После этого можно создавать расширения, которые подключаются к системе на уровне механизмов выполнения, перехватывая стандартные функции, например, ExecutorRun. Такой хук позволяет получать объект QueryDesc, содержащий подробности о запросе и запланированных операциях. Анатомия объектов QueryDesc и PlannedStmt Объект QueryDesc – центральный элемент, передаваемый хукам исполнения.
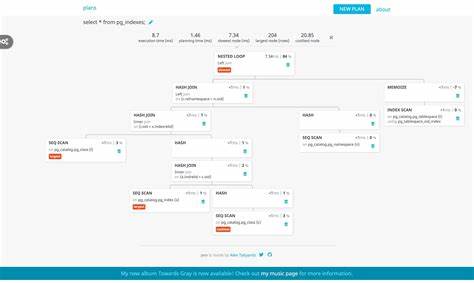
Он содержит поля, описывающие тип операции (выборка, вставка, обновление), непосредственно план (PlannedStmt), параметры запроса, состояние для выполнения и другую служебную информацию. PlannedStmt содержит подробное описание запланированного запроса, в том числе корень дерева Plan, которое отражает последовательность операций. План обычно представляет собой иерархическую структуру из специализированных узлов: SeqScan (последовательное сканирование), IndexScan (сканирование по индексу), Join (соединение), и многие другие. Каждый узел типа Plan содержит указатели на дочерние узлы и списки выражений для обработки. Перемещение по плану и расшифровка узлов Каждый узел плана имеет NodeTag, который позволяет определить тип узла.
По значению этого типа можно проводить операцию приведения указателя к конкретной структуре, соответствующей оператору. Для примера, тип 322 соответствует SeqScan – простому последовательному сканированию таблицы. Это дает доступ к relid (идентификатор таблицы), что в связке с rtable (список таблиц и алиасов, участвующих в запросе) позволяет определить имя таблицы. Распаковка условий фильтрации и списка выбираемых столбцов Информация о столбцах для выборки хранится в поле targetlist узла плана, который является списком TargetEntry-узлов. Каждый TargetEntry содержит внутреннее выражение, описывающее конкретную колонку или вычисляемое значение.
Фильтры, отвечающие за секцию WHERE, находятся в списке qual. Каждое условие представлено узлом выражения, например, OpExpr (операторное выражение), Const (константа), Var (переменная, ссылка на столбец таблицы). Обрабатывая эти узлы последовательно, можно восстанавливать исходные условия фильтрации со всеми операторами и значениями. Доступ к именам столбцов и операторов Для преобразования внутреннего представления столбцов Var в читаемые имена используется функция get_attname, которая по идентификатору таблицы и номеру столбца возвращает имя. Операторы, хранящиеся как OID, разрешаются с помощью SearchSysCache и таблицы pg_operator, где можно получить имена символов операторов, таких как >, <, = и др.
Таким образом, разнотипные узлы выражений можно обходить с помощью рекурсивных функций, восстанавливая из плана понятный формат SQL-запроса с указанием столбцов, таблиц и условий. Строительство SQL-строки из плана и буферизация Для последовательного построения итогового текста запроса применима концепция динамического буфера строк. Такой буфер позволяет эффективно собирать части строки (ключевые слова, имена, операторы, значения) и выводить готовую строку одним сообщение логирования, что повышает читаемость и удобство отладки. Благодаря этому можно отладочно выводить трансформированный план при каждом выполнении запроса, сверяя его с исходным текстом и анализируя, какие оптимизации были применены. Влияние понимания планов на оптимизацию и развитие проектов Владение знанием внутренней структуры планов запросов открывает двери для создания собственных средств анализа, мониторинга и даже альтернативных механизмов исполнения запросов.
К примеру, можно реализовать систему, которая перенаправляет выполнение части запросов на специализированные движки для колоночной обработки данных или векторные вычисления. Также понимание планов полезно для DBA при поиске узких мест в производительности запросов, оценке влияния индексов и правильной настройке параметров СУБД. Резюме Изучение и перехват планов выполнения запросов в PostgreSQL – мощный инструмент для профессионалов, стремящихся к глубокому контролю над процессом обработки данных. В сочетании с возможностями расширения через хуки, разработчики могут создавать сложные решения с кастомной интерпретацией и адаптацией поведения базы данных. Знание объектов QueryDesc, PlannedStmt, Plan и связанных структур позволяет писать эффективные средства восстановления и визуализации SQL-запросов на основе плана, облегчая анализ и оптимизацию.
Несмотря на некоторую сложность и отсутствие централизованной документации по всем хукам, практика и изучение исходного кода PostgreSQL вместе с использованием современных инструментов значительно упрощают задачу. Погружаясь в мир планов выполнения, специалисты обретают возможности для инноваций в области работы с данными, отладки и построения совершенно новых подходов к обработке SQL-запросов.