В мире технологий и искусственного интеллекта мы наблюдаем бесконечный рост интереса к языковым моделям, которые способны не только обрабатывать текст, но и генерировать его, часто не отличаясь от написанного человеком. Одним из ярких примеров этого является Yuan-1.0 — новая языковая модель, разработанная командой Shawn-IEITSystems. Yuan-1.0 является крупномасштабной предобученной языковой моделью с анонсируемыми 246 миллиардами параметров.
В основе ее успеха лежит идея, что для эффективного выполнения задач в области обработки естественного языка (NLP) необходимо сочетание масштабов моделей, объемов данных и вычислительных ресурсов. Однако, несмотря на впечатляющие результаты, расхождение в возможностях таких моделей, как GPT-3, создает значительные барьеры для исследователей, особенно когда речь идет о доступности вычислительных ресурсов. Создатели Yuan-1.0 решили использовать свои знания о распределенной обработке для оптимизации архитектуры модели. Эта инновационная стратегия позволила им обучить модель, использующую мощные вычислительные ресурсы, и достичь выдающихся результатов на различных NLP задачах.
Yuan-1.0 использует новый подход к обработке данных, который позволяет эффективно фокусироваться на отборе огромных объемов текстов с интернета, что немаловажно для создания качественных языковых моделей. В результате была собрана уникальная дата-сета объемом 5 ТБ, которая считается крупнейшей на сегодняшний день китайской текстовой корпусной коллекцией. Одной из сильных сторон Yuan-1.0 является ее способность к обучению в режиме Zero-Shot и Few-Shot.
Эти методы позволяют модели справляться с новыми задачами, используя минимальное количество примеров для обучения. Исследования, проведенные с использованием Yuan-1.0, показали, что модель стабильно показывает улучшенные результаты на различных NLP заданиях, таких как генерация текста, машинный перевод и анализ тональности. Интересно отметить, что тексты, созданные с помощью Yuan-1.0, сложно отличить от человеческих написаний, что подчеркивает уровень качества и надежности данной модели.
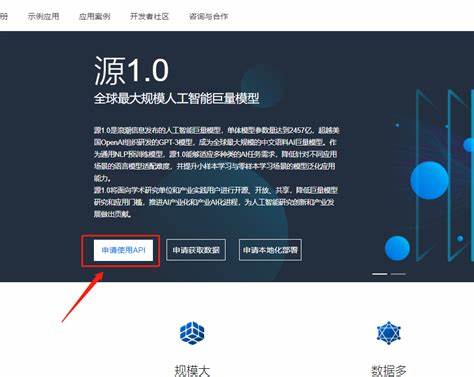
Разработчики Yuan-1.0 также сделали акцент на открытости. Они объявили о своей готовности предоставить доступ к 1 ТБ корпуса и API модели. Это значит, что теперь любой желающий может воспользоваться возможностями Yuan-1.0 для создания своих собственных приложений, что, безусловно, поможет развитию сообщества исследователей и разработчиков.
Для использования API пользователям потребуется зарегистрироваться на официальном сайте, где они смогут получить уникальный ключ доступа. Это открытие может быть решающим шагом в создании более открытой и доступной экосистемы для работы с языковыми моделями. На текущий момент Yuan-1.0 поддерживает разнообразные приложения, в том числе генерацию диалогов, продолжение текста, создание поэзии и извлечение ключевых слов. Например, для создания диалога пользователю достаточно просто ввести текст, и модель сгенерирует ответ, как если бы он был написан человеком.
Параметры, которые не упоминаются в документации, по умолчанию принимают стандартные значения, что делает использование API удобным и доступным даже для начинающих программистов. Однако, несмотря на все достижения, проект Yuan-1.0 не лишен вызовов. Разработка и тренировка языковых моделей такого масштаба требуют огромных финансовых и вычислительных ресурсов. Для многих исследователей это может стать серьезной преградой.
С другой стороны, в последние годы наблюдается рост интереса со стороны государств и частных компаний к инвестициям в искусственный интеллект и машинное обучение, что создаёт новые возможности для исследования сфер, связанных с языковыми моделями. Также стоит упомянуть значимость Yuan-1.0 в контексте научных исследований. Быстрое развитие языковых моделей открывает новые горизонты для лингвистов, социологов и исследователей в области коммуникаций. С помощью таких инструментов, как Yuan-1.
0, учёные смогут исследовать, как языковые структуры изменяются в зависимости от контекста, и как искусственный интеллект может влиять на восприятие текста. Наконец, весомым достижением Yuan-1.0 является тот факт, что она делает значительный вклад в развитие китайского языка в области технологий. Рост интереса к китайскому языковому контенту и возможность создания более качественных текстов на этом языке может способствовать улучшению коммуникации и пониманию между культурами. Важно отметить, что проект также иллюстрирует усиление позиций Китая в глобальной гонке в области искусственного интеллекта.
В целом, Yuan-1.0 представляет собой значимый шаг в развитии языковых моделей. С её возможностями и инновационным подходом команда Shawn-IEITSystems определенно меняет правила игры в мире обработки естественного языка. Открытие доступа к API и корпусу данных лишь способствует дальнейшему развитию данной области и создаёт новые возможности для сотрудничества и инноваций среди исследователей и разработчиков по всему миру. Если вы ещё не знакомы с Yuan-1.
0, самое время узнать о последнем слове в технологии языковых моделей и оценить, как оно может изменить вашу жизнь и работу.