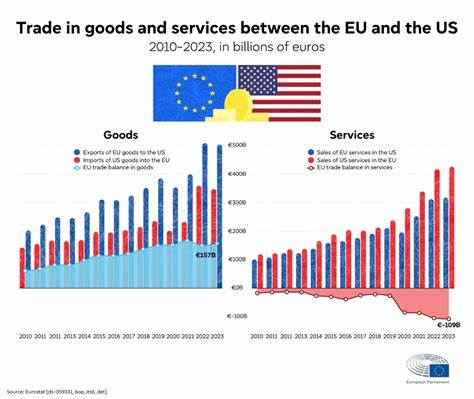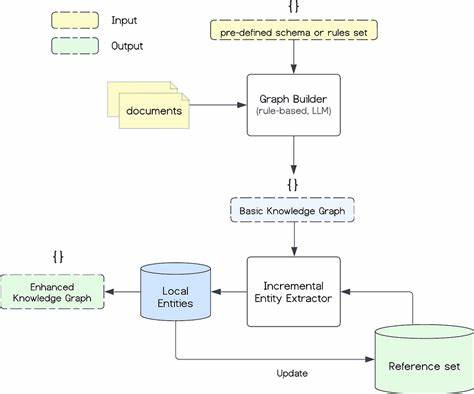
Современные языковые модели достигли впечатляющих результатов в различных сферах, включая математическое рассуждение, генерацию текстов и логический анализ. Тем не менее, их обучение и донастройка зачастую связаны с высокой стоимостью и сложностями, обусловленными необходимостью человеческого участия. Поиск решений, способных сократить эти издержки при сохранении или даже улучшении эффективности, стал острой задачей для исследователей и практиков. Одним из потрясающих прорывов в этой области стала методика улучшения моделей без надзора через максимизацию внутренней когерентности (Internal Coherence Maximization, ICM) в сочетании с оптимизацией на основе прямых предпочтений (Direct Preference Optimization, DPO). Эта инновационная технология открывает путь к самостоятельному развитию языковых моделей, позволяя им максимально полно использовать свои уже заложенные внутренние способности и знания без привлечения внешних оценок или аннотаций.
Традиционные методы улучшения языковых моделей, такие как обучение с подкреплением от человеческой обратной связи (Reinforcement Learning from Human Feedback, RLHF) и различные варианты обучения на основе предпочтений, требуют дорогостоящих и объемных данных, сформированных экспертами. Не исключено, что субъективность человеческой оценки и неоднородность в качестве данных могут снижать стабильность и качество конечной модели. Более того, настройка моделей на специфические задачи потребляет значительные ресурсы, а создание релевантных и достоверных аннотаций становится узким местом масштабирования. В ответ на эти вызовы исследователи разработали подход, который опирается исключительно на внутреннюю согласованность и логику самой модели. Метод ICM нацелен на нахождение взаимопредсказуемых и логически взаимосвязанных меток в данных, базируясь на заложенных внутри моделей представлениях и знаниях.
Вместо того чтобы полагаться на внешний сигнал оценивания, модель сама определяет, какие ответы и решения соответствуют её внутреннему пониманию задачи. Это эквивалентно тому, что модель ведет внутренний диалог, стремясь максимально устранить противоречия и повысить согласованность в своих суждениях. Для эффективного применения ICM важно создание разнообразного набора кандидатов решений. В отличие от простого использования единственно корректных ответов, разнообразие ответов разной степени правильности позволяет системе обучаться определять истинно логичные и обоснованные результаты. Этот ключевой момент обеспечивает баланс между истинными и ошибочными ответами, что создает более устойчивую базу для последующего обучения.
После формирования подобного набора данных с проверочными утверждениями идет этап преобразования результатов ICM в пары предпочтений, которые служат обучающим материалом для оптимизации модели с помощью DPO. Таким образом, модель переходит от внутренней оценки своих суждений к внешнему совершенствованию, выстраивая градацию предпочтений между более качественными и менее качественными ответами. Эксперименты, проведённые на базе моделей Qwen3 и Gemma3, показали значительные преимущества такого подхода. Без привлечения ни одного человека или обученной наградной модели, усовершенствованные алгоритмы ICM+DPO смогли превзойти результаты современных методов с человеческим надзором, таких как Group Relative Policy Optimization (GRPO). Особенно впечатляющим стал прирост в математическом рассуждении — до 11% по ключевым метрикам качества.
Более того, способности более мощной модели успешно перенеслись на менее мощную, давая ей возможность улучшить свои характеристики в сложных задачах. Несмотря на очевидные успехи, данный метод пока что проявляет определенные ограничения. Во-первых, он лучше всего работает в тех задачах и доменах, где изначально модель имеет накопленные знания и понимание, способное быть извлеченным через внутреннюю когерентность. Во-вторых, специфика алгоритма требует тщательной настройки параметров, включая генерацию разнообразных решений, что сложно выполнить без глубокого понимания процесса. Наконец, такая сфокусированность на конкретных областях знаний может приводить к незначительному снижению универсальных спобностей модели, что требует дробного подхода к применению данного метода в разных контекстах.
Несмотря на это, преимущества ICM+DPO трудно переоценить. Отсутствие необходимости в человеческой аннотации и обучении наградных моделей делает эту технологию чрезвычайно масштабируемой и рентабельной. Благодаря согласованию внутреннего понимания модели с её поведением, подход избавляется от ошибок аппроксимации, свойственных традиционным RLHF-методам. Кроме того, возможность переноса знаний между моделями открывает перспективы для быстрых улучшений даже слабых систем. Ключевой фактор успеха — это не просто обучение модели отвечать правильно, а её способность выстраивать внутреннюю систему истин и ложь, формируя самоподдерживающийся механизм обучения и проверки.
Теоретические исследования недавно подтвердили, что такие качественные изменения можно достичь не только через дообучение, но и через целенаправленное вмешательство на этапе вывода модели, что значительно расширяет горизонты для усовершенствования существующих систем без затрат на переобучение. Практическая применимость ICM+DPO закрепляется и открытым доступом к ресурсам, включая исходные коды, обучающие наборы данных и обученные модели. Это обеспечивает исследователям и разработчикам возможность быстро воссоздавать эксперименты, адаптировать методику под собственные задачи и развивать технологию. Данный шаг в сторону прозрачности и совместной работы также ускорит прогресс в области создания умных и адаптивных ИИ-систем. В будущем возможны расширения метода на ряд новых направлений.
Среди них — мультидоменные реализации, сочетающие компетенции разных областей, итеративное применение ICM и DPO для постепенного повышения качества, а также адаптация к креативным задачам, таким как генерация кода или речи. Также перспективным является использование параметрически эффективных техник, позволяющих минимизировать потерю общих знаний при специализации модели. Наконец, с развитием технологии ICM+DPO мы наблюдаем переход от традиционного парадигмы обучения с опорой на внешние источники информации к самостоятельному эмерджентному обучению. Модель начинает восприниматься как независимый агент, способный извлекать и уточнять своё знание, реализовывать самокоррекцию и рационализировать решения. Это фундаментально меняет подходы к разработке языковых моделей, демонстрируя потенциал для создания более автономных, надежных и эффективных систем искусственного интеллекта.
Подводя итог, метод максимизации внутренней когерентности в совокупности с прямой оптимизацией предпочтений открывает новую главу в эволюции языковых моделей. Отказ от дорогостоящих человеко-зависимых процессов в пользу глубинного понимания и саморегуляции моделей обещает масштабируемость, устойчивость и расширение возможностей ИИ в самых разнообразных сферах. В ближайшие годы эта технология наверняка станет одним из ключевых двигателей прогресса, способствуя разработке интеллектуальных систем, которые учатся и совершенствуются, ориентируясь исключительно на собственное внутреннее знание и логику.