В эпоху стремительного развития искусственного интеллекта большие языковые модели (LLM) становятся ключевым элементом во многих приложениях - от чат-ботов до сложных систем анализа текста. Однако при развертывании таких моделей разработчики и инженеры сталкиваются с проблемами, связанными со значительной задержкой холодного старта - временем, необходимым для загрузки модели в память GPU перед началом инференса. Эта задержка напрямую влияет на пользовательский опыт и масштабируемость систем. В ответ на эти сложности компания NVIDIA разработала Run:AI Model Streamer - высокопроизводительный SDK, позволяющий значительно сократить время загрузки моделей и ускорить начало работы инференса. Понимание основных причин возникновения холодного старта и эффективных способов его минимизации имеет решающее значение для компаний, внедряющих масштабируемые системы на основе больших языковых моделей.
Основная проблема связана с тем, что весы современных LLM занимают десятки и сотни гигабайт в памяти, что требует значительных усилий и времени для их переноса из хранилища данных в память GPU. Традиционные методы загрузки происходят последовательно и включают сначала считывание весов из дискового или облачного хранилища в оперативную память CPU, а затем передачу этих данных в память графического процессора. Такой поэтапный и последовательный процесс становится узким местом, особенно когда требуется обработка непредсказуемого спроса на вычисления, например, при высокой нагрузке в облачных системах или в динамично масштабируемых инференс-окружениях. Run:AI Model Streamer предлагает иную архитектуру работы, применяя многопоточность и параллелизм. Вместо последовательного чтения и передачи весов, он разбивает этот процесс на конвейер, позволяющий одновременно читать данные с диска и передавать уже загруженные части модели в память GPU.
Такой подход использует преимущества отдельных подсистем CPU и GPU и шины PCIe, позволяя графическому процессору напрямую обращаться к памяти CPU без дополнительного вмешательства центрального процессора. Благодаря этому достигается реальное перекрытие операций ввода-вывода и передачи данных, что существенно снижает время холодного старта. Для разработчиков важна совместимость с уже применяемыми форматами весов моделей. NVIDIA Run:AI Model Streamer поддерживает популярный формат safetensors, широко используемый для хранения LLM, без необходимости конвертации файлов. Это означает, что интеграция с существующими пайплайнами и инструментами, такими как vLLM и Tensor Generation Inference (TGI), становится максимально простой и прозрачной.
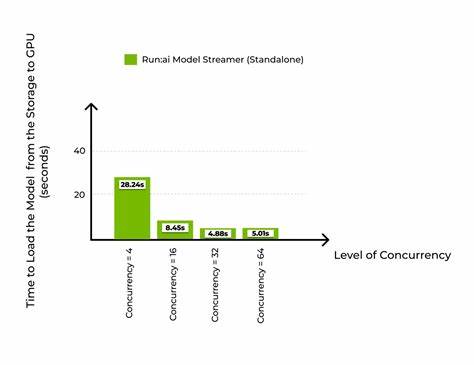
В рамках исследований и тестирований Run:AI Model Streamer сравнивался с двумя другими популярными загрузчиками моделей - Hugging Face Safetensors Loader и CoreWeave Tensorizer. Эксперименты проводились с моделью Llama 3 8B, вес которой составляет порядка 15 ГБ, на нескольких типах хранилищ, включая локальные SSD GP3 и IO2, а также облачное хранилище Amazon S3. Результаты показали, что при низкой параллельности Model Streamer загружает модель со скоростью сопоставимой с Safetensors Loader, однако с увеличением числа потоков до 16 достигается максимальная пропускная способность дисковых систем и загрузка модели ускоряется в несколько раз. Например, на дисках GP3 SSD время загрузки модели снижалось с 47-50 секунд до почти 14 секунд, а на более производительных IO2 SSD время падало до 7-8 секунд. По сравнению с CoreWeave Tensorizer, Model Streamer проявил большую стабильность и более эффективное использование сетевого и дискового ввода-вывода, особенно при интеграции с облачным хранилищем Amazon S3.
С облачными хранилищами связана дополнительная сложность - необходимость предварительного скачивания весов модели в локальное хранилище, что добавляет задержки. Здесь преимущество Model Streamer особенно заметно: он поддерживает потоковую загрузку из сетевых и облачных источников с возможностью параллельного чтения и передачи данных, значительно снижая время ожидания. По сравнению с Tensorizer, Model Streamer на S3 достигал почти пятикратного улучшения по времени загрузки - около 5 секунд против более 37 секунд у Tensorizer при оптимальных настройках. Интеграция Model Streamer с инференс-движком vLLM позволила оценить не только время загрузки, но и общее время до готовности системы к обслуживанию запросов. Такие комплексные метрики важны для практического применения, учитывая необходимость не просто загрузить модель, а подготовить систему для инференса максимально оперативно.
На локальных SSD GP3 и IO2 Model Streamer и Tensorizer сокращали общее время запуска почти вдвое по сравнению с традиционным Safetensors Loader. На S3 Model Streamer сохранял значительное преимущество, подтверждая свою эффективность для облачных сред. Выводы, основанные на результатах тестирования, однозначны - эффективное использование многопоточности и конвейерного подхода к загрузке весов из различных типов хранилищ может существенно устранить проблему холодного старта больших языковых моделей. Технология NVIDIA Run:AI Model Streamer демонстрирует готовое и практическое решение, позволяющее не только ускорить процесс старта инференса, но и максимально задействовать доступные ресурсы хранения и вычислительной системы. Для разработчиков и компаний, строящих решения на основе больших языковых моделей, это означает возможность быстрее вывести систему в рабочее состояние, повысить качество пользовательского опыта за счёт снижения задержек и улучшить масштабирумость приложений.
В условиях постоянно растущих объемов данных и сложности моделей, минимизация времени загрузки становится ключевым конкурентным преимуществом. Использование Model Streamer также хорошо сочетается с другими инновациями NVIDIA в области инфраструктуры и виртуализации GPU, включая технологии управления ресурсами Run:AI и оптимизации памяти для моделей. Это позволяет построить гибкую и адаптивную платформу для ИИ-инференса, которая эффективно реагирует на динамические нагрузки и оптимизирует распределение вычислительных ресурсов. Таким образом, снижение задержки холодного старта с помощью NVIDIA Run:AI Model Streamer является важным шагом к созданию быстрых и отзывчивых систем на базе больших языковых моделей. Интеграция данного SDK не требует сложных переделок в существующих пайплайнах, при этом обеспечивает заметный прирост в скорости загрузки и времени отклика.
Для специалистов, работающих с LLM, использование современных параллельных загрузчиков весов - не просто оптимизация, а необходимость для обеспечения стабильности и эффективности рабочих решений в эпоху мощных и масштабных искусственных интеллектов. .