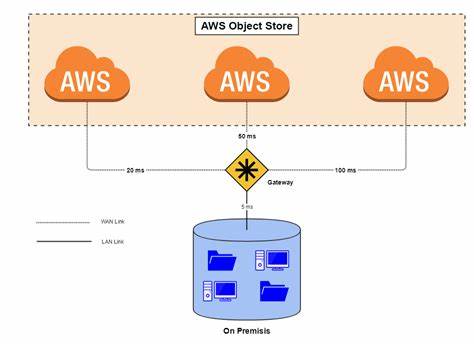
Производительность облачных хранилищ при работе с малыми объектами имеет огромное значение для приложений, которые ежедневно обращаются к огромному количеству маленьких файлов. Это могут быть лог-файлы, метаданные, небольшие блоки данных, AI-фичи или миллиарды крошечных объектов, которые должны обрабатываться с максимальной скоростью и надёжностью. Понимание того, как различные платформы справляются с такой нагрузкой, позволяет принимать обоснованные решения при выборе технологий для бизнес-задач. В отличие от работы с большими объектами, где пропускная способность сети и стабильность соединения играют решающую роль, при малых файлах главным становится минимизация задержек и оптимизация операций записи и чтения. В рассматриваемом бенчмарке, для оценки скорости и эффективности использовался широко применяемый Yahoo Cloud Serving Benchmark (YCSB), дополненный поддержкой совместимых с S3 сервисов.
Все тесты проводились на нейтральном облачном провайдере с одинаковыми параметрами аппаратного обеспечения, что исключает влияния факторов, связанных с конфигурацией инфраструктуры. С помощью YCSB была проверена работа с десятью миллионами объектов размером по одному килобайту, что позволило получить репрезентативную картину производительности облачных хранилищ в высоконагруженных сценариях. Особое внимание в исследовании было уделено двух этапам: первичной загрузке данных, когда все 10 миллионов объектов записывались в хранилище, и смешанному рабочему процессу, состоящему из миллиона операций с превалированием чтения (80%) над записью (20%). Эти этапы имитируют реальные рабочие нагрузки, с которыми сталкиваются современные приложения. Среди выявленных при тестировании тенденций выделяется выдающаяся производительность Tigris, достигающая задержек на чтение менее 10 миллисекунд и записи менее 20 миллисекунд.
Впечатляет и пропускная способность — в среднем в ходе смешанной нагрузки он достигает примерно 3300 операций чтения в секунду и 800 операций записи, что примерно в четыре раза превышает показатели AWS S3 и в двадцать раз — Cloudflare R2. Архитектурные особенности Tigris сыграли ключевую роль в достижении таких результатов. Они включают в себя технологию инлайнинга очень маленьких объектов непосредственно в метаданные, что сокращает число дисковых операций, снижает накладные расходы и ускоряет доступ. Дополнительно используется механизм объединения соседних ключей, позволяющий сокращать издержки на хранение, а также кэширование горячих элементов с применением LSM-структур в кеширующей подсистеме, что существенно повышает производительность при повторных обращениях к данным. В сравнении с S3 и R2, где задержки на запись мелких объектов достигают десятков и даже сотен миллисекунд, Tigris демонстрирует стабильность и минимальный разброс в параметрах времени отклика.
Особенно заметна разница с Cloudflare R2, чья 90-процентная задержка при записи превысила 340 миллисекунд — значение, способное значительно ухудшить работу пользовательских сервисов и увеличить время ожидания. Загрузка данных также выявила важные различия. Tigris завершил загрузку 10 миллионов объектов за чуть более 6700 секунд, тогда как AWS S3 показал результат почти на треть хуже — свыше 8800 секунд. Cloudflare R2 отставал более чем в 10 раз, что подчёркивает сложности этой платформы с обработкой массовых последовательных операций по малым объектам. Такая разница объясняется именно архитектурными отличиями и эффективностью системных оптимизаций, которые в случае Tigris срабатывают особенно хорошо.
Особое значение имеет величина пиковых задержек. Приоритет при работе с малыми объектами отдаётся не только средней скорости, но и стабильности отклика. В легковесных сценариях, где каждое обращение к объекту влияет на скорость отклика приложения, критично иметь минимальные значения в 50-ом и 90-ом процентилях, чтобы избежать «узких мест». Tigris уверенно удерживает высокие позиции по этим параметрам, обеспечивая задержки на уровне 7-8 миллисекунд при чтении и 16-17 миллисекунд при записи в 90% случаев. Для сравнения, AWS S3 располагается в пределах 40-42 миллисекунд, а Cloudflare R2 показывает значения, которые в десятки раз выше и неприемлемы для задач с высокими требованиями к скорости.
Эти показатели формируют устойчивое преимущество для Tigris, позволяя использовать его как единое решение для смешанных рабочих нагрузок с объектами разного размера. Благодаря улучшенной управляемости, более плотной упаковке данных и интеллектуальному кэшированию можно отказаться от необходимости использовать отдельные системы для различных типов объектов. Это экономит ресурсы, упрощает архитектуру приложений и ускоряет развитие продуктов. Важно также отметить, что bенчмарк проводился без особых оптимизаций со стороны провайдеров, что подчёркивает объективность результатов и применимость выводов для широкой аудитории разработчиков и инженеров. Для компаний, которым приходится обрабатывать большие объёмы мелких данных, высокая производительность с минимальными задержками означает возможность реализации более отзывчивых систем, улучшенное взаимодействие с пользователями и снижение затрат на инфраструктуру.
Примеры таких сценариев включают хранение логов, которые создаются постоянно и в большом количестве, AI-фичи, взаимодействие с метаданными в системах управления контентом, мобильные приложения с частыми операциями записи и чтения пользователя. В этих областях достижение минимальной задержки — среди приоритетных задач, от которых зависит успех конечного продукта. Для профессионалов, рассматривающих варианты выбора облачного хранилища, сделанные на основе глубоких сравнительных испытаний выводы представляют практический интерес. Tigris демонстрирует, что современные технологии способны решать задачи, которые ранее вызывали сложности у лидеров рынка. Более эффективная работа с малыми объектами открывает новые возможности для создания инновационных приложений и развития облачных сервисов в целом.
В заключение можно сказать, что грамотное использование архитектурных преимуществ и внедрение инноваций в области управления данными позволяют сервисам, таким как Tigris, успешно конкурировать с устоявшимися гигантами и даже превосходить их в специализированных сценариях. Понимание таких различий и взвешенный подход к выбору платформы обогатят практику разработки и менеджмента, приведут к снижению издержек и улучшат конечный пользовательский опыт, что критично в эпоху цифровой трансформации и масштабных данных.