В современном мире искусственного интеллекта большие языковые модели (LLM) становятся главными драйверами прогресса в обработке естественного языка. С ростом размера моделей и сложности задач остро встает вопрос об эффективном и быстром инференсе - процессе получения ответов модели на входные запросы. Одной из инновационных разработок, способных обеспечить высокую пропускную способность и масштабируемость при инференсе, является система vLLM. Это программное обеспечение открывает новые горизонты в управлении нагрузками, оптимизации вычислений и организации работы с большими языковыми моделями, предоставляя пользователям быстрый и удобный доступ к генеративным возможностям ИИ. Система vLLM разработана специально для обеспечения высокопроизводительного инференса и ориентирована на сценарии, где требуется обрабатывать множество запросов параллельно, сводя к минимуму задержки и максимизируя использование доступных ресурсов GPU.
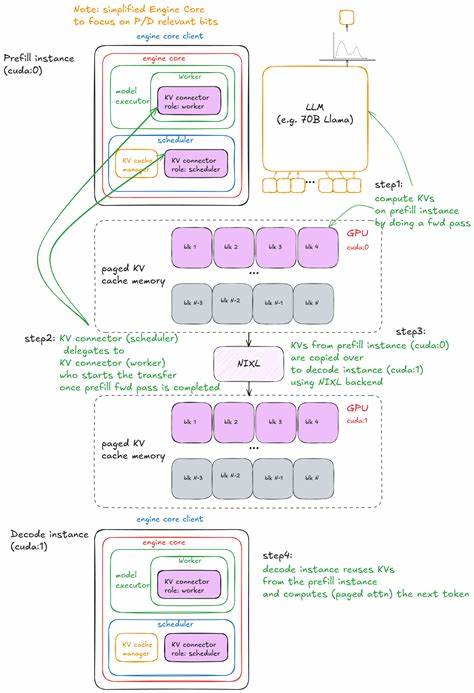
Она предлагает комплексное решение, объединяющее инновационные методы управления памятью, распределения задач и встроенного кэширования, чтобы обеспечить бесперебойную работу даже на гигантских моделях с миллиардами параметров. В архитектуре vLLM центральную роль играет так называемый движок LLM Engine, который отвечает за обработку входных данных, проведение вычислений и выдачу результатов. Он строится на базе Engine Core - ядра, курирующего внутренние процессы. Важнейшими его элементами являются процессор, обрабатывающий запросы, исполнитель модели (Model Executor), управляющий продвижением вычислений, а также менеджер кэша KV Cache Manager, который оптимизирует повторное использование промежуточных результатов. Процессор занимается преобразованием сырых входных запросов в формат EngineCoreRequests.
В ходе этого этапа происходит тщательная валидация, токенизация и подготовка данных для последующих этапов инференса. Это позволяет эффективно готовить запросы к обработке, а также поддерживать гибкость при разнообразии форматов ввода. Движок исполнитель (Model Executor) берет на себя задачи запуска вычислительных операций модели. На текущем уровне развития используется UniProcExecutor - один процесс-работник на одной GPU, постепенно переходя к реализации MultiProcExecutor, которая позволит эффективно распределять нагрузку между несколькими видеокартами, что крайне важно для масштабируемых систем. Ключевым элементом, делающим vLLM особенно эффективным, является продвинутое управление кэшем KV Cache (Key-Value Cache).
Эта технология позволяет сохранять и повторно использовать вычисленные представления для уже обработанных токенов, сокращая время повторного вычисления при генерации длинных последовательностей. Кэш организован по блокам, и система обеспечивает грамотное управление свободными и используемыми блоками, а также поддержку механизмов подсчета ссылок для предотвращения потерь данных и обеспечения целостности кэша. Каждый Worker - процесс, который инициализируется с назначением конкретного CUDA-устройства, осуществляет настройку съема и использования видеопамяти, а также загружает нужную модель с необходимыми параметрами. Такой подход предоставляет возможность тонко регулировать использование ресурсов GPU, что позволяет не просто достигать высокой производительности, но и обеспечивает устойчивость и масштабируемость. При взаимодействии с моделью используется объект модели раннер (Model Runner), который скрывает сложности работы с PyTorch, управляет буферами для входных данных и промежуточных результатов, выполнением самой модели и сбором результатов.
В рамках Model Runner реализуются также специализированные методы для поддержки ускоренных режимов вычислений, таких как CUDA-графы, позволяющие минимизировать накладные расходы на запуск операций. Для организации очередности запросов и выбора оптимальной стратегии обслуживания используется планировщик (Scheduler). В текущей реализации доступна политика "Сначала пришел - сначала обслужен" (FCFS), а также приоритетное планирование, которое может учитывать важность отдельных запросов при определении порядка их выполнения. Планировщик ведет учет очереди ожидающих и выполняющихся задач, обеспечивая балансировку и эффективное распределение ресурсов. Подача запросов для генерации текста происходит через удобный интерфейс метода generate, который автоматически управляет пакетной обработкой и учитывает ограничения по памяти.
Пользователь может задавать параметры семплинга, такие как температура и топ-p, что позволяет гибко контролировать разнообразие и качество генерируемого текста. Внутренние механизмы обеспечивают валидацию, токенизацию и добавление запросов в движок для обработки. Инженерным достижением vLLM является сквозное использование асинхронных механизмов и прогрессивных стратегий исполнения, что позволяет снижать задержки, эффективно запускать модель по частям и обеспечивать плавное обслуживание большого числа параллельных запросов. Благодаря продвинутому управлению памятью и повторному использованию вычисленных результатов достигается значительное ускорение обработки, позволяющее использовать крупные модели в продуктивных системах без существенной потери в скорости. vLLM содержит богатый набор параметров конфигурации, позволяющих пользователю тонко настраивать поведение системы.
Это включает режим токенизации, поддержку различных типов квантования для оптимизации памяти и скорости, настройки распределенных вычислений с применением Data Parallelism, Tensor Parallelism и Pipeline Parallelism. Такой уровень кастомизации дает возможность встраивать vLLM практически в любую инфраструктуру, адаптируя под конкретные задачи и аппаратное оснащение. Тщательная интеграция с PyTorch под поверхностью обеспечивает надежную работу и расширяемость. vLLM поддерживает загрузку и запуск моделей в привычном формате, использует возможности аппаратного ускорения и совместим с разными типами модернизаций, включая лёгкие адаптации весов LoRA. К тому же, в системе реализованы средства мониторинга, профилирования и сбора статистики, для анализа производительности и оперативного выявления узких мест.
Еще одной значимой особенностью является структурированное управление выводом, что позволяет организовывать направленное декодирование и применение грамматических масок, улучшая качество и контролируемость генерации. Это полезно в случаях, когда важна корректность и соответствие с заданными правилами, например, при создании диалоговых систем или обработке специфичных форматов. В целом, vLLM представляет собой передовое решение для высокопроизводительного инференса LLM, сочетающее в себе мощные инженерные наработки, гибкость конфигурации и широкие возможности масштабирования. Система показывает, как комплексное и продуманное проектирование может преодолеть многие сложности, связанные с обработкой больших моделей, делая их эффективным инструментом в коммерческих и исследовательских приложениях. Использование vLLM открывает новые возможности для разработчиков и исследователей, позволяя интегрировать крупные языковые модели в продукты с высокими требованиями к скорости и масштабируемости.
Она доказала свою эффективность на примерах генерации текста, обработки больших объемов запросов и адаптации под сложные аппаратные конфигурации. Так как индустрия ИИ продолжает развиваться, востребованность систем как vLLM будет лишь расти. Ее инновационные подходы к оптимизации инференса и управления вычислительными ресурсами закладывают фундамент для создания новых поколений платформ, способных обслуживать все более глубокие и мощные модели, приближая возможности искусственного интеллекта к практическому и повсеместному применению. .