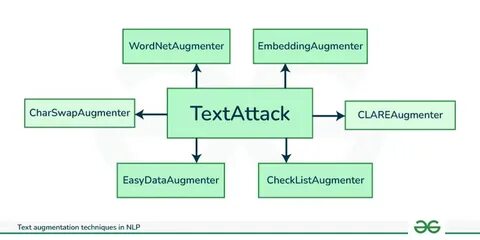
Современная индустрия машинного обучения непрерывно развивается, и одной из важных задач в её рамках является создание эффективных и компактных моделей, способных сохранять высокую точность при уменьшенных ресурсных затратах. Одна из современных методик, призванных решить эту задачу - дистилляция моделей. Этот процесс предполагает передачу знаний от большой, высокопроизводительной модели - учителя - к более компактной модели - ученику. Однако для успешной дистилляции необходимы качественные и разноплановые данные, которые способны раскрыть весь потенциал возможностей модели-ученика. Именно тут на сцену выходит DeepFabric - новый инструмент, занимающийся генерацией структурированных синтетических наборов данных, предназначенных для эффективной дистилляции моделей.
DeepFabric представляет собой платформу, способную создавать уникальные синтетические датасеты, разработанные с учетом конкретных требований задач и архитектур моделей. Ключевая особенность DeepFabric заключается в генерации структурированных данных, которые максимально приближены к реальным, но при этом не требуют сбора и аннотирования больших объемов настоящих данных. Это особенно важно в сферах, где получение и обработка реальных данных могут быть дорогостоящими, трудоемкими или связанными с проблемами конфиденциальности. Использование синтетических данных не ново в области машинного обучения, однако DeepFabric существенно расширяет возможности таких подходов благодаря своей фокусировке на структурированности и контролируемой вариативности создаваемых датасетов. Это позволяет не только снизить зависимость от реальных данных, но и нацельно влиять на качество и характер обучающих примеров, что положительно сказывается на конечной эффективности модели.
Одной из важнейших составляющих успеха DeepFabric является глубокое понимание принципов построения датасетов с точки зрения статистики и структуры данных. В отличие от случайных или плохо продуманных синтетических генераторов, DeepFabric обеспечивает создание многоаспектных и репрезентативных выборок, охватывающих разнообразные паттерны и зависимости. Это становится особенно ценным в задачах слаборазмеченных данных, где каждая дополнительная информация существенно повышает качество обучения. Для разработчиков и исследователей DeepFabric представляет собой мощный инструмент, который помогает преодолеть узкие места, связанные с нехваткой качественных данных. В условиях растущей конкуренции и необходимости быстрой разработки адаптивных моделей доступ к таким данным становится критическим фактором успешного внедрения технологий ИИ в различные отрасли экономики.
Благодаря DeepFabric процесс подготовки моделей для промышленного применения становится быстрее и дешевле, одновременно снижая риски, связанные с возможными пробелами в обучающей выборке. Генерация синтетических структурированных данных с помощью DeepFabric имеет широкий спектр применений. В медицинской области, где существует строгий контроль над доступом к персональным данным пациентов, использование синтетических датасетов позволяет создавать обучающие наборы, которые сохраняют основные статистические и клинические особенности, но не раскрывают конфиденциальную информацию. Для финансового сектора DeepFabric помогает обучать модели на разнообразных сценариях рынка, моделируя редкие и экстремальные события, что без такого инструмента было бы крайне сложно. Кроме того, DeepFabric значительно ускоряет процесс экспериментов с новыми архитектурами моделей.
Возможность быстро генерировать данные, адаптированные под конкретные тесты, помогает быстрее выявлять сильные и слабые стороны моделей, оптимизировать гиперпараметры и общую стратегию обучения. Это особенно важно для команд, занимающихся исследованиями и разработкой новых алгоритмов, где скорость итераций напрямую влияет на конкурентоспособность. Технически DeepFabric построен на основе передовых алгоритмов генерации данных, включая использование моделей глубинного обучения, способных имитировать сложные зависимости и закономерности в датасетах. Платформа поддерживает настройку ключевых параметров генерации, что дает возможность подстраивать синтетические данные под индивидуальные требования задачи. Пользователи могут задавать сценарии, уровни шума, распределения признаков и другие характеристики, формируя уникальный материал для обучения моделей.
Кроме генерации данных, DeepFabric интегрируется с инструментами для дистилляции и дообучения моделей, что обеспечивает полный цикл работы над улучшением качества и эффективности моделей. Такой комплексный подход делает платформу ценной не только для академических исследований, но и для практических решений в бизнесе и промышленности. В мире, где данные считаются новой нефтью, DeepFabric предлагает инновационный путь: синтетические данные как эффективный ресурс для создания высококачественных моделей искусственного интеллекта. Возможность управления структурой и детализацией данных открывает новые горизонты для дистилляции моделей и повышения их производительности без значительных затрат и нарушений конфиденциальности. Подытоживая, DeepFabric - это не просто генератор синтетических данных, а полноценный инструмент, меняющий правила игры в области машинного обучения.
Его применение помогает научным коллективам и коммерческим компаниям ускорять инновации, расширять возможности моделей и минимизировать риски, связанные с ограничениями в реальных данных. Благодаря таким технологиям будущее ИИ становится более доступным, адаптивным и этичным, что способствует развитию умных систем в различных сферах жизни. .