В современной цифровой эре, где каждая секунда downtime может привести к значительным убыткам, эффективное реагирование на инциденты становится ключевым фактором для поддержания стабильности и надежности сервисов. Несмотря на кажущуюся очевидность необходимости иметь отлаженные процессы, чрезмерная регламентация зачастую превращается в тормоз, замедляющий критически важные операции. Рассмотрим, почему процесс в некоторых случаях становится латентностью и как грамотно оптимизировать ритм реагирования, чтобы повысить общую эффективность команд. Опыт специалистов и лучшие практики из крупных технологических компаний, таких как Google, демонстрируют, что гибкость и адаптивность играют не менее важную роль, чем чётко прописанные инструкции. В условиях высокого стресса и ограниченного времени важно не просто следовать багтрекерам и чек-листам, а уметь принимать решения на основе текущей ситуации, сохраняя при этом согласованность действий всех участников процесса.
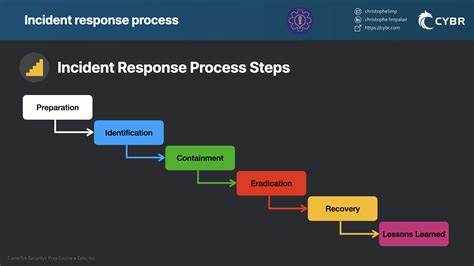
Одной из ключевых проблем избыточного формализма является рост латентности. Когда Incident Commander вынужден листать длинные документы в поисках точного совпадения с описанием проблемы, теряется драгоценное время, которое можно было бы потратить на быстрое оценивание ситуации и реализацию мер по сдерживанию и разрешению инцидента. Такой подход хорошо работает в теории, но на практике может привести к замедлению реакции и увеличению простоя. Оптимальный подход заключается в создании структурированной, но гибкой системы реагирования. В основе лежат универсальные рамки и общие принципы, позволяющие команде понимать свои роли, последовательность действий и цели, не застревая в деталях.
Важную роль играют понятия жизненного цикла инцидента и функций, таких как выявление, эскалация, коммуникация и восстановление. Именно эти элементы формируют скелет процесса, вокруг которого могут появляться адаптивные сценарии под конкретные запросы. Например, две компании могут иметь разные подходы к информированию руководства в случае критического сбоя, но обе цели преследуют идентичные — держать ключевых лиц в курсе и получать от них необходимую поддержку. Такая унификация терминологии и главных концепций облегчает взаимодействие и ускоряет реакции вне зависимости от масштаба или характера инцидента. Одновременно с этим важно избегать чрезмерной жесткости.
Попытка прописать каждую потенциальную вариацию проблемы и создать для нее отдельный регламент приводит к накоплению документов, которые сложно своевременно обновлять и которые часто воспринимаются командой как обременительные. Руководители в таких случаях сталкиваются с дилеммой: поддерживать документацию в актуальном состоянии или сосредоточить усилия на непосредственном решении проблем. Более того, в некоторых критических случаях избыточная бюрократия превращается в серьёзный барьер. Обязательные многоступенчатые согласования, как правило, затягивают процесс принятия решений и могут стать причиной значительных задержек при реагировании на быстроразвивающиеся угрозы. Поэтому ключ к успешной оптимизации ритма реагирования — баланс между процессом и гибкостью.
Необходимо разработать базовый план с четко прописанными ключевыми ролями и этапами, который одновременно можно легко адаптировать под новые, нестандартные ситуации. Такой подход позволяет Incident Commander использовать свое профессиональное суждение, опираясь на общий каркас, избегая при этом паралича анализа. Также фундаментальное значение имеет культура компании и подготовка специалистов. Все участники процессов должны быть обучены работать с неопределённостью, уметь быстро анализировать доступные данные и принимать сбалансированные решения. Внедрение регулярных тренировок, симуляций и разборов инцидентов поможет команде развить этот навык, снижая когнитивную нагрузку в реальных ситуациях.
Автоматизация также выступает важным инструментом ускорения реакции. Современные системы мониторинга и оповещения способны отбирать и передавать только наиболее релевантную информацию, тем самым снижая объем данных, с которыми сталкивается команда. Также автоматические процессы могут выполнять рутинные задачи, освобождая ресурсы специалистов для решения более сложных проблем, требующих человеческого участия и интуиции. Важно отметить, что подход к реагированию должен постоянно пересматриваться и улучшаться на основе обратной связи и анализа прошлых инцидентов. Каждая сложная ситуация — это урок, выявляющий слабые места в существующих процессах и открывающий возможности для оптимизации.
Формирование культуры постоянного улучшения позволяет избежать повторных ошибок и создавать все более адаптивные и эффективные механизмы реагирования. В конечном итоге, успешная оптимизация ритма реагирования на инциденты — это искусство, сочетающее в себе структуру и баланс, дисциплину и гибкость, технологические средства и человеческий фактор. Такие стратегии способны значительно уменьшать время простоя, минимизировать потери и повышать доверие пользователей и бизнеса к цифровым сервисам. Подводя итог, следует считать, что слишком жесткие процессы способны превратиться в латентность, замедляющую критически важные действия. С другой стороны, отсутствие единой системы ведет к хаосу и неопределенности.
Результатом становится умелое сочетание стандартизированных каркасов, адаптивных сценариев, обученной команды и инструментов автоматизации. Именно такая комплексная модель гарантирует высокий темп реагирования и качество разрешения инцидентов в условиях высокой неопределенности и стресса. В современном мире, где скорость реакции во многом определяет стабильность бизнеса, организация эффективного и сбалансированного процесса управления инцидентами становится не просто техническим требованием, а основой конкурентного преимущества. Сфокусированный на оптимизации ритма реагирования подход помогает компаниям оставаться на шаг впереди непредвиденных сбоев, поддерживая высокие стандарты надежности и устойчивости эксплуатации цифровых решений.