Современные информационные системы и приложения генерируют огромное количество логов, которые необходимо эффективно обрабатывать и анализировать для обеспечения стабильной работы, быстрого выявления ошибок и мониторинга производительности. При этом традиционные методы парсинга логов зачастую оказываются слишком медленными, ресурсоемкими или не масштабируются под объемы данных, возникающих в крупных инфраструктурах. В ответ на эти вызовы появилась инновационная разработка — Arrow-Powered Log Parser, которая кардинально изменяет подход к работе со структурированными логами, позволяя превращать их в высокоэффективный аналитический формат Apache Arrow. Что же делает этот инструмент настолько уникальным и ценным для специалистов, работающих с данными, разработчиков и системных администраторов? Давайте разбираться. В основе Arrow-Powered Log Parser лежит идея интеграции с Apache Arrow — открытым стандартом колоночного формата данных в памяти, который обеспечивает низкую латентность и высокую пропускную способность при обработке больших объемов информации.
Благодаря такому подходу парсер не просто читает и разбирает логи, а напрямую конвертирует их в формат, идеально подходящий для аналитики в современных системах, включая популярные инструменты как DuckDB, Polars и pandas. Это позволяет свести к минимуму затраты на преобразование данных и использовать имеющиеся вычислительные ресурсы максимально эффективно. Парсер разработан на языке Go и обладает нулевыми внешними зависимостями, что обеспечивает легкость сборки и удобство интеграции в различных операционных средах. За счет этого его очень просто внедрять в существующие пайплайны обработки данных, минимизируя время установки и настройки. Кроме того, программное решение поддерживает стриминговую обработку, что позволяет работать с большими файлами логов без существенного увеличения потребления памяти.
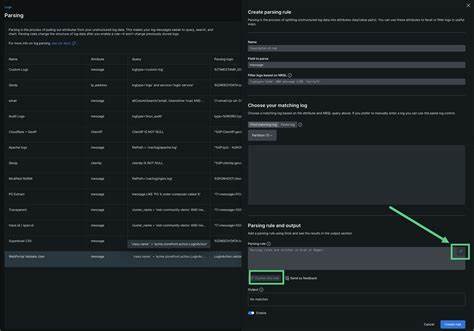
Такая эффективность критически важна для систем, где обработка данных происходит в реальном времени или близка к нему. Для превращения текстовых логов в структурированные данные Carve использует механизм регулярных выражений с именованными группами захвата. Это инновационное решение делает процесс определения схемы данных простым и интуитивно понятным, позволяя пользователю заранее описать структуру логов с помощью удобного синтаксиса. При этом все поля автоматически определяются как строки, что позволяет избежать сложностей с типами на начальном этапе парсинга. Порядок полей в результирующем файле совпадает с порядком указанных именованных групп, сохраняя логику и последовательность исходных данных.
Благодаря возможности настраивать размер батчей — количества строк, обрабатываемых за один раз — можно гибко оптимизировать использование памяти и производительность парсера в зависимости от конкретных условий. Типичные рекомендации предполагают значения от 1000 до 100000 строк в батче, что позволяет добиться высокого уровня производительности без риска перегрузки оперативной памяти. Такой баланс особенно важен при работе с гигабайтными и терабайтными массивами логов. Важной особенностью Arrow-Powered Log Parser является его тесная интеграция с аналитическими платформами. Например, файлы в формате Arrow можно напрямую загружать в DuckDB для выполнения SQL-запросов, анализируя распределение уровней ошибок, выявляя временные закономерности и исследуя специфические текстовые паттерны в сообщениях.
Для Python-пользователей инструмент совместим с pandas и Polars, что открывает широкие возможности для последующей обработки и визуализации лога, а zero-copy интерфейс минимизирует накладные расходы и время загрузки данных. Одной из сильных сторон этой технологии является скорость обработки. Benchmarks показывают, что небольшой лог объемом менее мегабайта можно распарсить со скоростью около 10 МБ в секунду. Для средних файлов объемом до 100 МБ скорость достигает 50 МБ в секунду, а большие объекты свыше 100 МБ обрабатываются со скоростью до 100 МБ в секунду. Такая производительность существенно превосходит аналогичные инструменты и открывает новые возможности для оперативного анализа больших потоков логов.
Инструмент поддерживает режим детальной отладки, который поможет обнаружить строки, не соответствующие заданному шаблону regex. Это позволяет глубже понять структуру и качество исходных данных, устранить потенциальные ошибки и обеспечить чистоту и корректность итогового набора данных. При этом по умолчанию неподходящие строки игнорируются, что не мешает работе парсера, но может быть критично в случаях, когда требуется полный контроль над входными данными. В будущем разработчики планируют реализовать расширенные возможности, в том числе автоматическое определение типов полей для более точной типизации данных, поддержку мультистрочных логов, различные форматы вывода данных, включая JSON, CSV и Parquet. Также предстоит внедрение механизмов компрессии и оптимизации для еще более эффективной обработки больших потоков информации.
Использование Arrow-Powered Log Parser уже сегодня помогает компаниям повысить скорость и качество анализа логов, снижая издержки на инфраструктуру и упрощая интеграцию с современными инструментами обработки данных. Его применяют для мониторинга корпоративных приложений, веб-серверов, систем безопасности и в различных сценариях, где важна оперативность и точность анализа. Подводя итог, можно сказать, что Arrow-Powered Log Parser — это мощный инструмент нового поколения для парсинга и аналитики логов. Он предлагает уникальное сочетание высокой производительности, удобства использования и интеграции с широко распространёнными аналитическими платформами. Для специалистов, работающих с большими объемами данных, заинтересованных в оптимизации процессов и снижении времени реакции на инциденты, это решение становится незаменимым помощником.
Его открытый исходный код, отсутствие внешних зависимостей и гибкая конфигурация делают его привлекательным и доступным для внедрения в любые ИТ-ландшафты. Развитие проекта обещает появление новых функций, которые расширят область применения и сделают процесс работы с логами еще более эффективным и удобным. Оценить возможности и начать использовать данный парсер можно прямо сейчас, клонировав репозиторий и выполнив сборку инструмента — это позволит уже сегодня значительно поднять уровень аналитики логов и обрести конкурентные преимущества в сфере обработки данных.