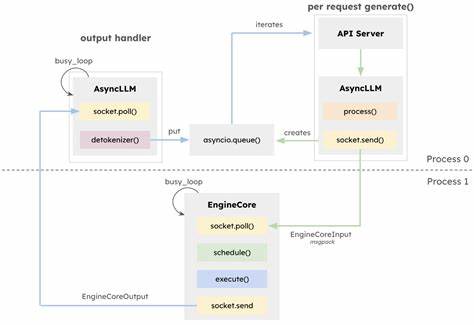
vLLM продолжает занимать важное место в экосистеме инструментов для инференса и обслуживания больших языковых моделей (LLM), предлагая уникальный набор функций для пользователей и разработчиков. В начале 2025 года сообщество vLLM представило крупное обновление своей основной движка и архитектуры — vLLM V1, который призван повысить масштабируемость и гибкость системы без ущерба для основных возможностей. В синергии с технологической платформой AMD ROCm и линейкой графических процессоров AMD Instinct MI300X достигнуты значительные прорывы в производительности и эффективности работы. Освещение новшеств архитетуры vLLM V1 помогает понять, почему обновление стоит использовать и как оно влияет на реальный опыт в обработке больших моделей. Одна из главных изменений в архитектуре V1 связана с оптимизацией выполнения и переосмыслением серверного API.
Асинхронная обработка задач позволяет эффективно разграничивать нагрузку между CPU и GPU. В ранних версиях vLLM (v0) многие вычислительно сложные операции, связанные с токенизацией и предварительной обработкой изображений, мешали отделать GPU, создавая узкие места. В V1 этот процесс стал более независимым и неблокирующим, что обеспечивает значительно более высокий уровень использования вычислительных ресурсов GPU и уменьшает задержки, особенно для мультимодальных моделей, где требуется интенсивная подготовка данных на стороне CPU. Такая архитектурная переоснова открывает путь для масштабирования систем и обработки запросов с низкой латентностью, что крайне важно для современных AI-приложений. Новая версия отличается упрощённым механизмом планирования заданий.
В отличие от предыдущей версии, где токены распределялись между фазами prefill и decode раздельно, V1 использует более гибкий подход с фиксированным бюджетом токенов, что позволяет реализовывать продвинутые функции, такие как chunked-prefill и prefix-caching, по умолчанию. Chunked-prefill означает, что система может обрабатывать токены ввода и генерации выхода параллельно, существенно сокращая время до вывода первого токена (TTFT) – ключевой показатель для качества интерактивных систем. Prefix-caching же позволяет кэшировать префиксы запросов, что ускоряет повторное использование ранее вычисленных результатов и снижает нагрузку на вычислительные ядра. Эти функции значительно оптимизируют отклик и пропускную способность, что подтверждается экспериментальными данными при работе с крупными моделями, такими как Llama-3.3-70B.
Поддержка программного обеспечения ROCm от AMD заметно упрощает использование новых возможностей vLLM V1. Значительная часть высокопроизводительных функций включена по умолчанию, что снижает порог входа для пользователей и разработчиков. Выбор режима работы достаточно легко конфигурируется за счёт переменных окружения и аргументов командной строки, позволяя при необходимости вернуться к версии V0 или отключить определённые оптимизации, например, prefix-caching или chunked-prefill. Особое внимание уделяется поддержки FP8 формата для key-value кеша, который в настоящее время включён по умолчанию, но может быть активирован для повышения эффективности памяти и скорости при работе с большими языковыми моделями, особенно в условиях ограниченных вычислительных ресурсов. Одним из важных направлений в развитии vLLM V1 стало улучшение мультимодальных возможностей.
Современные мультимодальные модели, например Qwen2-VL-7B-Instruct, способны объединять визуальную и текстовую информацию для создания интерактивных диалогов и ответов на сложные вопросы, что требует эффективной обработки непрерывных эмбеддингов. Ранее в v0 такие эмбеддинги сложно было оптимизировать из-за полной работы механизма внимания для энкодеров, а запросы предполагались полностью предзаполненными. V1 вносит инновации в виде encoder cache и специального планировщика, который учитывает особенности энкодера и обеспечивает хранение эмбеддингов напрямую в GPU-кеше, снижая нагрузку на CPU и улучшая баланс вычислений. Это нововведение приводит к значительному сокращению общей задержки и повышению скорости отклика в режиме онлайн-обслуживания с разными уровнями нагрузки, что подтверждено внутренними тестами AMD с использованием Qwen2.5-VL-7B-Instruct.
Время до появления первого токена (TTFT) традиционно оставалось проблемой для современных систем с обработкой больших последовательностей ввода и вывода, особенно при жёсткой взаимозависимости между фазами предзаполнения и декодирования. V1 с интегрированным chunked-prefill позволяет моделям параллельно обрабатывать входные и выходные токены, тем самым значительно сокращая TTFT и улучшая общую отзывчивость системы. В сравнении с V0 среднее время до первого токена снижено примерно на четверть при сохранении сопоставимой точности и стабильности. Несмотря на некоторые вариации распределения задержек, преимущество chunked-prefill очевидно при масштабировании по одновременной нагрузке. Кроме того, общая пропускная способность системы на V1 демонстрирует рост от 25 до 35 процентов по сравнению с V0 при одинаковой задержке, особенно при работе с крупными моделями и многопроцессорных конфигурациях, например с 8 AMD Instinct GPU.
Практические рекомендации по работе с vLLM V1 включают ряд утилит и команд для быстрого развертывания и тестирования производительности. Использование официальных Docker-образов ROCm vLLM упрощает реализацию и эксперименты для пользователей, позволяя выбрать версию движка и активировать необходимые режимы оптимизации. При этом благодаря поддержке моделей в публичных репозиториях, таких как Hugging Face, использование крупных языковых моделей не требует дополнительной авторизации, что значительно облегчает старт работы. Тестирование показало устойчивые результаты по снижению задержек и улучшению пропускной способности на эталонных моделях Llama 3.3-70B, что подтверждает применимость архитектурных инноваций на практике.
В заключение, vLLM V1 представляет собой значительное архитектурное улучшение, кардинально повышающее эффективность запуска крупных языковых моделей на современных вычислительных платформах, особенно на базе GPU AMD Instinct серии MI300X. Благодаря асинхронному исполнению, улучшенному планировщику с chunked-prefill и prefix-caching, а также поддержке мультимодальных функций и новых форматов данных, vLLM V1 выводит LLM-инференс на новый уровень производительности. Развитие этого направления продолжается, и впереди работы по созданию высокопроизводительных attention-ядр для chunked-prefill с поддержкой FP8 в рамках проекта ROCm AITER. Следить за обновлениями и вносить свой вклад помогут ресурсы и репозитории ROCm AITER на GitHub. Для компаний и специалистов, заинтересованных в применении LLM в продуктивных средах, обновление до vLLM V1 открывает новые возможности оптимизации параметров и достижения лучших показателей отклика и пропускной способности.
Таким образом, vLLM V1 — это не только технологический скачок, но и пример тесного взаимодействия сообщества и индустрии для решения актуальных задач в машинном обучении и искусственном интеллекте. Его архитектурные изменения и оптимизации способны удовлетворить растущие требования к скорости и масштабу современных LLM-приложений, обеспечивая стабильность и гибкость эксплуатации в разнообразных сценариях использования.