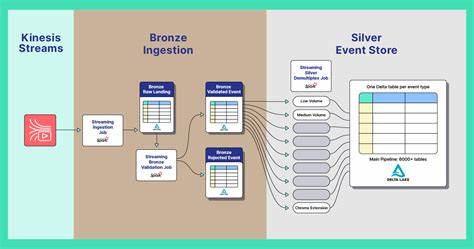
Современные распределенные системы, ориентированные на обработку событий, требуют надежного приема и передачи сообщений для обеспечения масштабируемости и скорости отклика. В основе таких систем часто лежит сервис приема событий — специализированный компонент, который получает, проверяет и направляет сообщения в дальнейшие подсистемы. Говоря об организации тестирования подобного сервиса, важно учитывать уникальные особенности событийно-ориентированной архитектуры и сложность взаимодействия компонентов в рамках различных сред разработки и эксплуатации. Сервис приема событий выполняет роль шлюза, принимая сообщения от внешних производителей через облачную шину событий. Для обеспечения масштабируемости и надежности при работе с большими объемами данных предпочтительно использовать управляемые облачные сервисы, предоставляющие удобные SDK для программного взаимодействия с шиной.
Основные задачи сервиса включают прием сообщений в форматах, таких как JSON, проверку их соответствия схеме и целостности данных, а также корректное направление валидных сообщений на внешние системы для дальнейшей обработки. Тестирование критически важно для гарантии стабильной работы сервиса во всех сценариях. Принято разделять процессы контроля качества по средам — Development (DEV), Test (TEST) и Integration (INT). Каждая из них решает свои задачи. В DEV происходит ранняя отладка функций, без подключения внешних систем, что снижает риски внешних сбоев.
TEST представляет собой контролируемую среду с автоматизированными тестами, также изолированную от внешних источников данных ради надежности тестирования. INT — это почти продакшен-среда, где upstream-система полностью подключена к шине событий, обеспечивая полноценное тестирование в условиях, имитирующих реальную эксплуатацию. Функциональное тестирование направлено на проверку ключевых возможностей сервиса. Специалисты оценивают способность приемника обрабатывать допустимые форматы сообщений, корректно валидировать схемы и отклонять некорректные или искаженные данные. Также важна проверка маршрутизации сообщений, чтобы исключить потери и повреждение информации при передаче на последующие компоненты.
В DEV и TEST для функционального контроля широко применяются автоматизированные инструменты, которые генерируют разнообразные сообщения: от стандартных до граничных случаев, включающих большие объемы, пропуски полей или неправильные типы данных. Сценарии выполняются с использованием облачного SDK, что позволяет программно отправлять сообщения и отслеживать реакцию сервиса. В INT среде, напротив, упор делается на ручное тестирование, где реальная upstream-система генерирует сообщения, что помогает выявить несовпадения с ожидаемыми схемами и оперативно корректировать валидационные правила приема. Проверка производительности сервиса крайне важна для обеспечения его работоспособности при интенсивных нагрузках. В DEV и TEST запускаются автоматизированные тесты с высокой нагрузкой, достигающей тысяч сообщений в секунду.
Они измеряют пропускную способность, задержки и способность сервиса масштабироваться за счет запуска дополнительных инстансов. Проводятся стресс-тесты, чтобы выявить пределы выносливости и потенциальные узкие места в архитектуре, а также тесты масштабируемости, подтверждающие возможность горизонтального расширения сервиса. В INT среде нагрузочное тестирование дополняется более реалистичными сценариями, где батчи сообщений отправляются от upstream-системы, имитируя пиковые нагрузки в продакшене, что позволяет оценить реальное поведение системы под давлением. Тесты надежности направлены на подтверждение устойчивости системы к сбоям и ошибкам. Автоматизированные средства в DEV и TEST создают условия сбоев, например, имитируют проблемы с сетью или рестарты сервисов для проверки восстановления из критических состояний.
Имитируется получение дублированных сообщений, чтобы убедиться, что сервис корректно обрабатывает повторы без сбоев downstream. Контроль целостности данных гарантирует отсутствие потерь и искажений. В INT среде выполняются ручные сценарии отключения и повторного подключения шины событий, проверяющие способность сервиса возобновлять обработку с последней контрольной точки, что жизненно важно для непрерывности бизнес-процессов. Интеграционное тестирование проводится преимущественно в INT среде и проверяет полноту прохождения сообщений от upstream-системы, через шину событий и сервис приема, до downstream-потребителей. На этапе интеграционного тестирования выявляются и устраняются проблемы несовместимости схем, например, различия в именах полей или типах данных между системами.
Также оценивается задержка и объемы обработки сообщений при реальных производственных нагрузках, что гарантирует согласованность и надежность работы всей цепочки. Для успешного тестирования важен выбор подходящих технологических инструментов. Использование облачного SDK позволяет программно управлять отправкой сообщений, создавать сложные сценарии тестирования и автоматизировать процессы в DEV и TEST. Управляемая облачная шина обеспечивает масштабируемый и надежный буфер для сообщений. Мониторинговые облачные решения следят за ключевыми метриками — задержками, объемом сообщений, ошибками, что важно для быстрой диагностики проблем.
Кастомные скрипты на Python с интеграцией SDK позволяют автоматизировать генерацию сообщений, эмуляцию сбоев и отслеживание результатов. Для ручного тестирования в INT задействуется нативный механизм генерации сообщений upstream-системы и облачные консоли для управления и мониторинга. Процесс приема и обработки сообщений можно представить последовательным потоком. Upstream-система или тестовые скрипты генерируют сообщения, помещая их в облачную шину событий, где они накапливаются в масштабируемой очереди. Сервис приема слушает эту очередь, валидирует структуру и целостность сообщений, разделяет корректные и ошибочные.
Корректные данные перенаправляются downstream, а ошибочные — логируются и отправляются в отдельный буфер ошибок для последующего анализа. Облачная инфраструктура поддерживает масштабируемость и отказоустойчивость всего процесса. В ходе тестирования было выявлено несколько ключевых проблем, требующих внимания. В INT среде интеграционные тесты выявили расхождения в схемах сообщений, что потребовало адаптации валидационных правил, обеспечив корректное взаимодействие между системами. Производительные тесты обнаружили узкие места в реализации многопоточности и ресурсов шины событий, решение которых достигнуто оптимизацией кода и увеличением количества логических разделов (partitions) в шине.
Тесты надежности выявили задержки при возобновлении обработки после коротких простоев шины, которые скорректировали за счет улучшенного механизмa контрольных точек. Ручное тестирование в INT оказалось трудоемким, что подчеркнуло необходимость расширения автоматизации комплексных E2E сценариев в будущем. Подводя итог, комплексный подход к тестированию сервиса приема событий в нескольких средах позволил добиться надежности и стабильности в эксплуатации. Автоматические тесты в DEV и TEST обеспечили качественную проверку базовых функций и производительности, тогда как ручные и интеграционные тесты в INT подтвердили правильность взаимодействия с upstream-системой и готовность к реальной эксплуатации. Баланс между автоматизацией и ручной проверкой, использование облачной инфраструктуры и продуманных скриптов стало залогом успешного внедрения сервиса в инфраструктуру предприятия.
Данный опыт демонстрирует важность многоэтапного тестирования и постоянного совершенствования методов проверки для построения надежных событийно-ориентированных систем нового поколения.