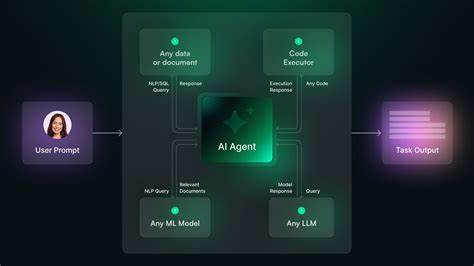
В современном мире разработки программного обеспечения эффективная обработка и анализ текстовой информации имеет огромное значение. Особенно это актуально при создании компиляторов, интерпретаторов и других программ, работающих с разными языками программирования или доменными специфическими языками. Среди разнообразия технологий и методик парсинга особое место занимают парсер-комбинаторы — простой, мощный и гибкий способ разработки парсеров, позволяющий создавать сложные синтаксические анализаторы с минимальными усилиями и в компактном коде. Парсер-комбинаторы — это функциональные строительные блоки, которые можно комбинировать друг с другом, образуя более сложные правила парсинга. Каждый из таких парсеров работает с состоянием входного текста и пытается сопоставить определённый шаблон.
Если сопоставление успешно, парсер возвращает результат и обновлённое состояние, позволяя следующим парсерам продолжить разбор оставшейся части текста. Если же сопоставление неудачно, то парсер сообщает об этом, что позволяет применять различные стратегии обработки ошибок или выбирать альтернативные варианты разбора. Одно из ключевых преимуществ парсер-комбинаторов — это прозрачность и структурированность кода. В отличие от традиционных парсеров, основанных на сложных таблицах или автоматах с конечными состояниями, комбинаторы легко реализуются в языках, поддерживающих функции первого класса и замыкания. Благодаря этому можно создавать парсеры, которые читаются почти как грамматика, что значительно упрощает поддержку и расширение анализа.
Основой любого парсер-комбинатора является понятие состояния. Состояние содержит текст, который должен быть обработан, и позицию (смещение) текущего анализа. Вместо изменения исходного состояния, парсер возвращает новый объект с обновлённым смещением — это гарантирует чистоту выполнения и облегчает управление ошибками и откатом в процессе разбора. Начинающие знакомятся с парсер-комбинаторами через самый простой пример — строгий матчинг конкретной строки. Такой парсер принимает на вход фрагмент текста и проверяет, совпадает ли он с заданной строкой, например с "hello".
Если совпадение происходит на текущей позиции, парсер возвращает результат и продвигает указатель вперед. Такой подход формирует базу для построения более сложных конструкций. Для обработки более свободных и разнообразных данных применяется парсер, сопоставляющий одиночный символ с заданным шаблоном. С помощью регулярных выражений или наборов символов можно создавать парсеры, способные находить цифры, буквы, пробелы и другие важные лексемы языка. Это особенно полезно при анализе идентификаторов, чисел и прочих элементов, не ограниченных фиксированным набором.
Следующим шагом являются парсеры-секвенции, которые последовательно применяют несколько подкомбинаторов, объединяя результаты. Например, для разбора арифметического выражения "7+8" можно построить парсер, который сначала извлечет число 7, затем символ '+', а после — число 8. Если все компоненты найдены успешно друг за другом, возвращается структурированное дерево, отражающее синтаксическую последовательность элементов. Не менее важной является возможность повторения. Парсер, способный распознавать повторяющиеся фрагменты — например, последовательность цифр, образующих число — даёт возможность обработать практически любые числовые значения любой длины.
Параметр минимального количества повторений позволяет регулировать жёсткость правила — от обязательного появления хотя бы одного элемента до непредельного количества. Иногда нужно обработать ситуацию, когда текст может соответствовать одному из нескольких вариантов. В этом случае применяется комбинатор выбора, который пробует каждый из возможных парсеров по очереди, начиная с первого. Такой подход исключает неоднозначность разбора, поскольку выбирается первая успешная альтернатива, что особенно важно в синтаксисах с жёстким предписанием приоритета. Одной из наиболее вдохновляющих особенностей парсер-комбинаторов является возможность реализовывать рекурсивные правила.
В отличие от простых регулярных выражений, рекурсивные правила позволяют создавать грамматики для языков с произвольной вложенностью, например, скобочные выражения или цепочку операций с разной ассоциативностью. Это достигается с помощью ссылок на другие парсеры, вызывающихся только во время выполнения, что снимает проблему взаимной зависимости объявлений. Кроме того, для получения удобочитаемых и функционально значимых результатов исходный разбор часто модифицируется различными функциями трансформации. Например, разобранные символы цифр можно преобразовать в целочисленные значения, а синтаксические конструкции — в структуры данных для дальнейшей обработки или интерпретации. Это значительно повышает прикладную ценность созданного парсера, позволяя сразу использовать результат для вычислений или анализа.
Главное достоинство парсер-комбинаторов — простота их использования и гибкость. Создать полнофункциональный парсер часто удаётся всего на нескольких десятках строк кода, что экономит время разработчиков и снижает вероятность ошибок. Благодаря модульности, каждый парсер-комбинатор можно тестировать и отлаживать независимо, улучшая качество итогового продукта. Стоит отметить, что парсер-комбинаторы идеально подходят для быстрого прототипирования и образовательных целей. Понимание их работы помогает глубже осознать принципы синтаксического анализа, а практическое применение позволяет освоить концепции голой грамматики, рекурсии и функционального программирования.
Классическим примером использования парсер-комбинаторов является создание парсера арифметических выражений с поддержкой цепочек операций и правил приоритета. С помощью рекурсивных вызовов и подхода с отложенной ссылкой на грамматические конструкции можно реализовать анализ выражений типа «7 + 8 + 9», получая при этом корректное дерево разбора. Для более сложных языков и задач парсер-комбинаторы могут использоваться совместно с лексерами, предварительно разбивающими текст на токены. Однако, возможна и полная реализация без промежуточной токенизации — анализ происходит посимвольно, что позволяет строить эффективные и гибкие парсеры с минимальным количеством вспомогательных структур. Парсер-комбинаторы основываются на семантике грамматик выражений (PEG), что обеспечивает детерминированность и устранение неоднозначностей за счёт жёсткого порядка выбора альтернатив.