Современные большие языковые модели (LLM) стремительно завоевывают рынки, улучшая качество интерактивных приложений, автоматизации и генерации контента. Но рост объёмов и сложности моделей создаёт вызовы по части производительности систем и скорости вывода токенов. В таких условиях на первый план выходит создание высокопроизводительных систем инференса, способных эффективно обрабатывать миллионы токенов в секунду с минимальными задержками. Одной из таких систем является vLLM - современный движок, который сочетает продвинутые алгоритмы с масштабируемой архитектурой, обеспечивая высокую пропускную способность и низкую латентность при работе с трансформерами. Разбор внутреннего устройства vLLM позволяет понять, как построена современная инфраструктура вывода LLM и какие технологии лежат в её основе.
В основе vLLM лежит движок, спрятанный за своим API, который ответственен за всю логику токенизации, батчинга, вычислений и управления памятью. Начинается всё с базовой версии единственного процесса и одной GPU, где движок инициализирует модель, загружает веса и создаёт кэши ключей и значений (KV-cache), которые критически важны для ускорения работы с последовательностями в трансформерах. Отдельным архитектурным элементом является менеджер KV-запросов (KV-cache manager), который реализует концепцию постраничного внимания (paged attention). Эта технология позволяет разбивать длинные последовательности на небольшие блоки, упрощая управление памятью и доступ к ней на GPU. Каждый блок хранится отдельно и индексируется через связанный список свободных блоков, что даёт возможность динамично распределять память по мере обработки новых токенов без необходимости копирования всего кэша.
Технология paged attention для vLLM - одна из базовых, позволяющая эффективно масштабировать работу с длинными входными последовательностями и совмещать в одном батче большое число запросов, даже если они отличаются по длине и стадии генерации. Отличительной чертой движка является поддержка непрерывного батчинга (continuous batching). В классической модели работы с трансформерами каждый запрос ждёт своей очереди; в vLLM новые и текущие запросы обрабатываются одновременно благодаря динамической балансировке на уровне планировщика. Алгоритм планирования запросов, встроенный в движок, делит поток запросов на две категории: префилл (начальная обработка всех токенов подсказки одним прогоном) и декодирование (шаги генерации новых токенов). Эта дифференциация важна, поскольку каждый тип запросов имеет разный профиль использования ресурсов: префилл - более вычислительно интенсивный, а декодирование - ограничено пропускной способностью памяти.
Продуманная работа планировщика позволяет смешивать оба типа запросов, оптимизируя загрузку GPU в реальном времени и снижая задержки вывода. Для очень длинных запросов vLLM реализует технику "чанкед префилл" - разбивку предварительного заполнения токенов на небольшие части. Это предотвращает блокировку вычислительных ресурсов одним длинным запросом и обеспечивает более равномерное распределение мощности среди конкурирующих заявок. Кроме того, важной оптимизацией служит префиксное кеширование (prefix caching). Оно позволяет избежать повторных вычислений кэша для общих префиксов нескольких запросов, что особенно актуально в системах с похожими начальными фразами.
Механизм построен на сравнении блоков токенов с помощью эффективных хеш-функций. Вместо перерасчёта KV-блоков для каждого запроса с одинаковым префиксом, система повторно использует уже вычисленные блоки, значительно повышая производительность на многообразных наборах запросов. Среди дополнительных функциональностей стоит отметить ограниченное управляемое декодирование (guided decoding) с применением конечных автоматов (FSM). Это позволяет накладывать ограничения на генерируемый текст, обеспечивая соответствие определённой грамматике или шаблону. Такой подход полезен для задач программирования, генерации кода или структурированных ответов, где важно строгое соблюдение синтаксиса.
Способmasking логитов с помощью грамматик запускается за счёт валидаторов состояний конечных автоматов и мягко подавляет запрещённые токены, не позволяя им появиться в ответах модели. Одной из ключевых инноваций vLLM является speculative decoding - методика ускорения генерации следующего токена, которая вводит модель-чемпиона меньшего размера (draft LM). Эта вспомогательная модель пытается заранее предсказать несколько следующим токенов, после чего основная, большая модель проверяет и подтверждает или отторгает эти предложения. Это позволяет минимизировать количество дорогостоящих полноразмерных проходов по модели и уменьшить время отклика без потери качества выходных данных. В vLLM реализованы несколько схем proposal, включая простейший n-граммовый метод и более продвинутые EAGLE и Medusa, которые меняют структуру модели или дополнительно учатся параллельному прогнозу токенов.
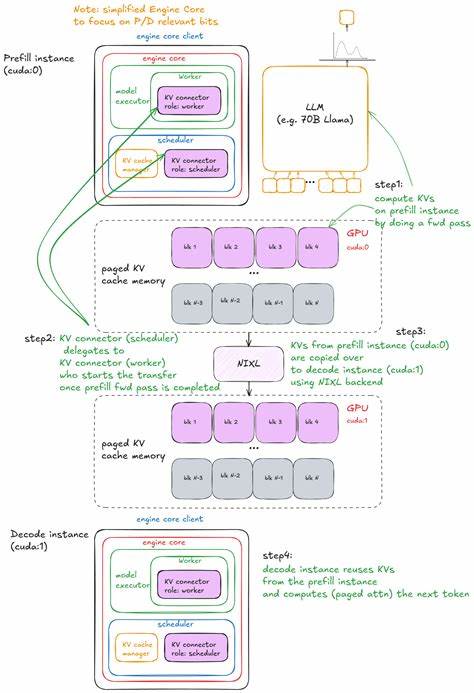
В реальных условиях нередко требуется разделять нагрузки префилла и декодирования. Для этого в архитектуре предусмотрено дисагрегированное выполнение P/D (Prefill/Decode), при котором отдельные инстансы системы обрабатывают предварительную обработку и генерацию токенов. Используется механизм передачи и синхронизации KV-памяти через абстракцию коннектор (connector), которая может реализовываться по-разному: например, через общий файловый сторедж, сетевые протоколы или специализированные кешевые решения. Такой подход позволят гибко масштабировать подсистемы, оптимизировать загрузку GPU и повысить отказоустойчивость кластера. Масштабирование vLLM выше одного GPU достигается с помощью MultiProcExecutor - менеджера нескольких процессов, каждый из которых обслуживает отдельный GPU, но работает согласованно, распределяя работу по шардированным весам модели через техники тензорного и пайплайн-параллелизма.
Для передачи команд и ответов между процессами используется очередь сообщений с поддержкой shared memory, а вторичные процессы формируют ответ для родителя, который абстрагирует их сложность. Это позволяет запускать модели размером в десятки или сотни миллиардов параметров на кластерах GPU с прозрачным интерфейсом. При масштабировании в многономсовых конфигурациях реализуется data parallelism (DP), где полные копии модели реплицируются на нескольких нодах, а запросы и результаты координируются отдельным слоем балансировки нагрузки и коммуникации. Для таких сложных конфигураций используется система DPEngineCoreProc и специальные менеджеры процессов, способные управлять связью через ZMQ, NCCL и другие коммуникационные протоколы. Движок включает асинхронный API для интеграции с веб-серверами, который через asyncio и различные очереди обеспечивает конкурентное выполнение множества запросов и передачу промежуточных результатов.
Обёртки AsyncLLM и DPLBAsyncMPClient координируют взаимодействия, а front-end, построенный на FastAPI и Uvicorn, скрывает всю сложность от конечного пользователя, которому достаточно отправить запросы стандартному HTTP API. Прозрачность и гибкость развёртывания в рамках vLLM позволяют легко добавлять новые инстансы API серверов и расширять вычислительные мощности, при этом балансировка нагрузки происходит на уровне сокетов и операционной системы, не требуя вмешательства приложений. Ещё одним важным направлением является мониторинг и оптимизация производительности. Система предлагает набор метрик, отражающих латентность (время до первого токена, межтокенистая задержка) и пропускную способность (число токенов в секунду). Баланс между этими метриками - сложная задача, так как увеличение батча снижает нагрузку на весовые операции, но увеличивает время отклика.
В vLLM реализованы бенчмарки, замеряющие latency, throughput и эмулирующие реальные пользовательские нагрузки через генераторы событий с пуассоновским распределением. Для удобства предусмотрен CLI-инструмент vllm bench с различными режимами и возможностью автотюнинга параметров, направленного на достижение нужных SLO (например, поддержание 99-го перцентиля latency ниже заданного порога). Архитектура и дизайн vLLM базируются на фундаментальных исследованиях в области эффективного управления памятью под задача инференса (таких как технология paged attention), встраивания поддержки различных моделей и современных аппаратных решений. Система поддерживает расширения, в том числе модели с модифицированной внимательной архитектурой (MLA), эксперты-слои (MoE), асинхронные алгоритмы планирования, и может работать как на GPU NVIDIA, так и на других ускорителях. vLLM демонстрирует, что высокая производительность решений для большого языка возможна не только за счёт оборудования, но и грамотного системного проектирования - это баланс алгоритмов, памяти, аппаратных коммуникаций и серверной архитектуры.
Выводы из изучения vLLM позволяют разработчикам и исследователям глубже понять внутренние процессы в инференс-системах, а также вдохновляют на внедрение подобных решений в своих продуктах и проектах. Совокупность уникальных эффектных техник, таких как paged attention, continuous batching, chunked prefill, prefix caching, speculative decoding и масштабируемая многопроцессорная обработка, делает vLLM удачным примером современного инженерного подхода к построению высокопроизводительных LLM-инфраструктур с открытым исходным кодом. В итоге vLLM не просто ускоряет генерацию ответов, а создаёт платформу, готовую к серьёзным вызовам индустрии с постоянно растущими требованиями к скорости, качеству и масштабируемости работы больших языковых моделей. .



![Turn a spreadsheet into a web app using Django and SQLite MCP [video]](/images/0A9F1578-CCA6-44EE-A4A5-F884A443C8EA)