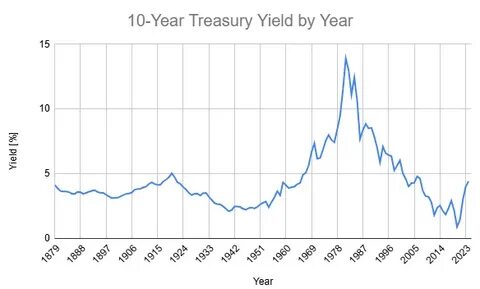
В последние годы развитие технологий искусственного интеллекта значительно ускорилось, и новейшие модели языковых систем вызывают большой интерес как у специалистов в области ИИ, так и у широкой аудитории. Дискуссии вокруг GPT-5 и его характеристик, а также сравнений с предшествующей GPT-4 сегодня получают особую актуальность. Один из ключевых вопросов заключается в том, почему новая модель, казалось бы, почти не отличается от предыдущей версии, несмотря на ожидания значительных улучшений и нововведений. Компьютерные инженеры, исследователи и пользователи искусственного интеллекта пытаются понять причины подобной стабильности в развитии моделей от OpenAI и выяснить, что это значит для будущих перспектив ИИ. Разберем главные факторы, объясняющие, почему GPT-5 оказался очень похожим на GPT-4 и почему подобная ситуация является закономерной в контексте эволюции нейросетей.
Начнем с технической стороны вопроса. Обычно крупные модели машинного обучения, такие как GPT, создаются на основе больших наборов данных и огромного количества параметров. Несмотря на впечатляющее число параметров, дальнейшее усложнение модели не всегда приводит к экспоненциальному улучшению качества работы. Существует несколько причин для этого. Во-первых, при достижении высокого уровня точности и глубины понимания модели, дальнейшие улучшения требуют непропорционально больших ресурсов.
Увеличение количества слоев или параметров ведет к увеличению вычислительной сложности, времени обучения и стоимости, давая лишь минимальный прирост в качестве ответа и понимании текста. Во-вторых, модели могут достигать точки, когда архитектура и тренировка становятся "узким горлышком": легче достичь прогресса с изменением самих принципов обучения, а не просто увеличением объёма данных и параметров. Кроме того, важным фактором является направленность компаний, занимающихся разработкой таких моделей, на надежность, безопасность и снижение рисков неправильного применения ИИ. Разработчики стараются минимизировать неожиданные побочные эффекты и опасные изменения в поведении модели. Это приводит к тому, что новые версии часто фокусируются на стабилизации, устранении ошибок и улучшении контроля за генерацией текста, а не на резких качественных скачках.
По сути, GPT-5 можно рассматривать как тщательно отшлифованную и оптимизированную версию GPT-4, где основная работа была направлена скорее на внутренние улучшения и повышение безопасности, а не на революционные нововведения. Таким образом, изменения в результатах работы модели становятся менее заметны для конечного пользователя. Следующий аспект - экономический. Разработка и запуск новых моделей требуют значительных инвестиций. В условиях высокой конкуренции на рынке продуктов ИИ, компании вынуждены тщательно оценивать баланс между затратами и ожидаемым эффектом.
Запуская GPT-5 с минимальными, но качественными усовершенствованиями, OpenAI сохраняет интерес аудитории и одновременно оптимизирует расходы. Кроме того, в некоторых случаях стабильность позволяет адаптировать модель для широкого спектра задач и интеграций без необходимости радикальной переподготовки систем и пользовательских интерфейсов. Психологический и маркетинговый аспекты также играют свою роль. Ожидания от новых версий всегда высоки. Если бы GPT-5 резко отличался от GPT-4, это могло бы вызвать осложнения в восприятии изменений, особенно если нововведения не всегда оказываются полезными для всех пользователей.
Сохраняя преемственность, компания минимизирует риски недовольства и облегчает адаптацию к новым особенностям. Кроме того, подчеркивая схожесть версий, можно сосредоточиться на долгосрочной стратегии развития, а не на "гонке за новыми цифрами". Потребители привыкают к качеству и функционалу, и такая стабильность воспринимается как признак надежности и продуманности продукта. Нельзя игнорировать и научно-исследовательские барьеры, встречающиеся на пути дальнейшего развития языковых моделей. Алгоритмические улучшения становятся все более сложными, и на сегодня многие методы уже испытаны практически до предела.
Новые подходы требуют серьезных экспериментов с архитектурой, новыми типами механизмов внимания, способов обработки контекста и потенциально радикального пересмотра принципов работы. Это все сохраняет текущий статус-кво и замедляет внедрение заметных изменений. Кроме того, общие вызовы в области искусственного интеллекта, такие как проблемы со смысловым пониманием, обобщением на случае, эффектом "галлюцинаций" и предвзятости в результатах, еще недостаточно решены, что ограничивает возможности для качественного прорыва. Обратим внимание и на роль внешних трендов и конкуренции. Другие компании и исследовательские институты также стремятся к совершенству языковых моделей, предлагая свои конструкции и решения.
Это стимулирует OpenAI укреплять уже доказанные концепции, улучшая стабильность и масштабируемость, а не рисковать непроверенными технологиями. В таком конкурентном поле постепенный прогресс зачастую эффективнее резких нововведений, особенно когда речь идет о продуктах, зависящих от доверия и надежности. С точки зрения пользователя, отсутствие значительных различий между GPT-4 и GPT-5 может казаться разочаровывающим. Однако это также свидетельствует о том, что нынешние модели достигли высокого уровня зрелости и надежности. Новая модель уже способна решать самые сложные задачи с впечатляющей точностью, демонстрируя многообразные возможности для применения в бизнесе, образовании, творчестве и науке.
В ближайшем будущем стоит ожидать, что инновации будут не столько в базовой архитектуре, сколько в интеграции ИИ с другими технологиями, расширении пользовательского опыта, а также более глубокой персонализации. Таким образом, схожесть GPT-5 и GPT-4 объясняется комплексом факторов - техническими ограничениями, экономической целесообразностью, заботой о безопасности и надежности, а также стадией развития самих моделей. Это закономерный этап в эволюции искусственного интеллекта, который подчеркивает зрелость существующих решений и подготавливает почву для будущих прорывов. Понимание этих причин помогает лучше оценить современное состояние области, а также формирует адекватные ожидания по отношению к развитию языковых моделей и их влиянию на будущее технологий и общества в целом. .