gRPC уже давно считается одним из ведущих инструментов для межсервисного общения в современных высоконагруженных приложениях. Он построен поверх HTTP/2, что обеспечивает поддержку множества параллельных потоков и эффективную передачу данных. Несмотря на это, разработчики YDB столкнулись с неожиданной проблемой: при работе в условиях сетей с минимальной задержкой производительность и время отклика системы ухудшалась при уменьшении числа узлов кластера. Анализ показал, что корень проблемы заключается не на стороне сети или сервера, а непосредственно в клиентской реализации gRPC. Для тех, кто не знаком с архитектурой gRPC, стоит отметить, что в клиенте существуют так называемые каналы (channels), каждый из которых поддерживает множество RPC-вызовов (т.
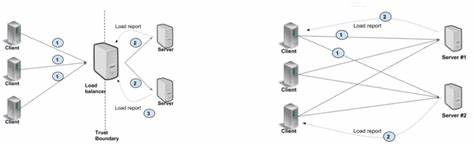
н. стримов) поверх одного или нескольких HTTP/2 соединений. При работе с несколькими каналами на разные серверы устанавливаются отдельные TCP-соединения, тогда как при создании каналов с одинаковыми параметрами они могут совместно использовать одно TCP-соединение и мультиплексировать вызовы внутри него. Это важный момент, который в дальнейшем сыграл ключевую роль в выявлении узкого места. В официальной документации по gRPC отмечается, что каждое HTTP/2 соединение имеет ограничение на число параллельных стримов, зачастую равное 100.
Если количество активных RPC на одном соединении достигает этого порога, новые запросы начинают ставиться в очередь, что негативно сказывается на общей производительности. Рекомендуемые подходы для высоких нагрузок включают создание выделенных каналов для наиболее нагружённых областей или использование пула каналов с уникальными параметрами, чтобы избежать повторного использования TCP-соединения. В YDB для нагрузки кластера применялся вариант с несколькими каналами, но при одинаковых параметрах, что приводило к неожиданному эффекту: все эти каналы использовали одно TCP-соединение и, как следствие, лимит параллельных стримов этой связи становился узким местом. В результате, несмотря на сильные серверные ресурсы и мощную сетевую инфраструктуру со скоростью 50 Гбит/с и минимальной задержкой менее 0,05 миллисекунд, производительность клиента оставалась далека от теоретического максимума. Пиковый рост пропускной способности при увеличении числа параллельных запросов в 10 раз составил лишь около 3,7 раза, а с увеличением числа клиентов в 20 раз – всего около 4 раз.
При этом задержка клиентских вызовов увеличивалась пропорционально количеству одновременно выполняемых запросов. Для тщательного анализа разработчики создали специализированный микробенчмарк на C++, использующий как синхронный, так и асинхронный API gRPC. Клиент запускался на отдельной машине, оснащённой двумя процессорами Intel Xeon Gold с 32 ядрами каждое и поддержкой гиперпотоков, что максимально приближало условия тестирования к реальным высоконагруженным системам. Использовался закрытый цикл запросов с минимальной нагрузкой на бизнес-логику: ping-запросы без полезной нагрузки, что позволило сфокусироваться на измерении накладных расходов коммуникационного стека. Распределение потоков и выполнение клиента происходили в рамках одной NUMA-узловой области с помощью утилиты taskset, что исключало влияние межузловых задержек памяти и контекстных переключений.
Такое деление аппаратных ресурсов на NUMA-области считается оптимальной практикой для точного измерения производительности в многопроцессорных системах. Анализ сетевого трафика с помощью tcpdump и Wireshark не выявил никаких проблем на уровне транспортного протокола: тенология Nagle отключена, TCP-окно достаточно велико, пакетная потеря отсутствовала. Сервер мгновенно обрабатывал запросы, а ACK посылались своевременно. Главным узким местом стала задержка на стороне клиента. Клиент посылал запросы пакетом, сервер отвечал серией пакетов, после чего наступал период молчания продолжительностью около 150-200 микросекунд, прежде чем клиент начинал новый запрос.
Такие интервалы ожидания значительно превышали задержку сети и накладывали ограничения на пропускную способность. Для проверки гипотезы о том, что проблема связана с совместным использованием TCP-соединения, инженеры экспериментировали с вариантами: создание каналов на каждого рабочего потока с одинаковыми параметрами, с разными параметрами и включением специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL. Результаты показали, что разделение каналов с разными параметрами или использование указанного аргумента разрешает проблему и обеспечивает заметное улучшение как по пропускной способности, так и по латентности. В режиме мультиканального подключения throughput вырос почти в 6 раз для обычных RPC и в 4,5 раза для стриминговых запросов, а задержка увеличивалась лишь незначительно при увеличении числа параллельных запросов. Стоит особо подчеркнуть, что подобная проблема заметно сглаживается в сетях с высокой задержкой, например, около 5 миллисекунд.
Там влияние клиентской блокировки на фоне сетевых задержек становится незначительным, и прирост производительности при разделении каналов уже не столь выражен. Значит, эта узкая точка характерна именно для сетей с минимальной задержкой, где накладки в программном обеспечении могут превзойти физическую задержку передачи данных. Выводы, к которым пришла команда YDB, имеют важное значение для всех разработчиков и архитекторов распределённых систем. Принятые официальные рекомендации по gRPC, предусматривающие создание отдельных каналов для областей высокой нагрузки или использование пулов каналов с уникальными аргументами, на самом деле являются частями одного общего решения: важно избегать совместного использования TCP-соединения между множеством параллельных RPC, чтобы не попасть под ограничение числа активных стримов HTTP/2 и избежать очередей на клиенте. Устранение этой проблемы позволяет добиться высокой пропускной способности при сохранении низкой задержки, что критично для систем с интенсивной коммуникацией и требовательных к времени отклика, таких как распределённые базы данных, микросервисные платформы и высокочастотные торговые системы.
Это открытие подчеркивает, насколько важна глубокая и системная оптимизация сетевого стека и клиентской логики в современных масштабируемых инфраструктурах. Помимо реализации с gRPC, подобный эффект может наблюдаться и в других протоколах с мультиплексированием поверх одного соединения, что делает обнаруженную причину и решение универсально полезными. Авторы YDB приглашают сообщество к обсуждению и совместному поиску дополнительных улучшений, предлагая к доступу свой лабораторный микробенчмарк для тестирования и экспериментов. Таким образом, для эффективного использования возможностей gRPC в сверхскоростных сетях необходимо тщательно настраивать клиентскую архитектуру: создавать отдельные каналы с уникальными параметрами или использовать современные настройки субканалов, чтобы избежать скрытых ограничений, связанных с протоколом HTTP/2. Внимание к таким деталям позволяет раскрыть весь потенциал сервисов и обеспечить плавное масштабирование при минимальных затратах на реагирование.
Опыт YDB доказывает, что оптимизация клиентской стороны коммуникации — не менее важная задача, чем совершенствование серверной части или настройка сетевого оборудования. Глубокое понимание внутреннего устройства gRPC и внимательное наблюдение за поведением системы в различных условиях по умолчанию разрывают шаблон «сети с низкой задержкой не могут быть узким местом», поскольку программный стек способен сам стать полноценным ограничением. Именно преодоление таких препятствий гарантирует создание эффективных, отзывчивых и масштабируемых распределённых систем будущего.