В условиях стремительного развития финансовых рынков и роста объёмов данных традиционные методы управления портфелями акций и других активов сталкиваются с вызовами, связанными с обработкой информации в режиме реального времени. Чтобы минимизировать риски и своевременно адаптировать стратегию, управляющие фондами и инвесторы всё чаще обращаются к современным технологиям потоковой обработки данных. Среди самых перспективных решений выделяются системы, построенные на базе Apache Kafka и Apache Flink. Эти инструменты позволяют не только получать и обрабатывать данные с минимальной задержкой, но и легко масштабировать инфраструктуру в соответствии с требованиями бизнеса и рынка. Рассмотрим подробнее, каким образом комплекс Kafka и Flink может трансформировать управление активами, используя пример портфеля ценных бумаг, ориентированного на рынок, подобный Касабланкской фондовой бирже.
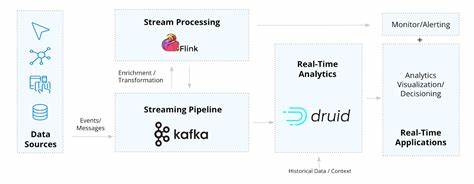
Этот рынок, несмотря на свою относительную невысокую частоту обновления информации, предоставляет достаточную среду для апробации комплексных потоковых систем и динамического перераспределения капитала. Ключевая задача подобных систем — сбор достоверных данных о ценах активов в режиме реального времени и оперативное пересчитывание значимых метрик, на основании которых происходит перераспределение пропорций вложений. Одним из главных аспектов является установка централизованной архитектуры для приема, передачи и обработки финансовой информации. Apache Kafka идеален для этой роли — он служит надёжным брокером сообщений, обеспечивающим высокую пропускную способность, устойчивость к ошибкам и упрощённое партицирование данных для параллельной обработки. Основной поток данных — это сведения о цене выбранных ценных бумаг, которые с регулярностью поступают в Kafka через продюсерские сервисы.
Для согласованности формата применяется AVRO-схема, которая гарантирует, что сообщения будут правильно десериализованы и интерпретированы в последующих этапах обработки. Помимо котировок, в Kafka транслируются сведения о текущих весах портфеля и статистические показатели, например, матрица ковариаций и средние доходности, что позволяет горизонтально интегрировать все данные в единую систему. Разработка продюсеров, ответственных за считывание и преобразование данных, сопряжена с необходимостью сохранения производительности и согласованности. Поскольку многие локальные рынки не предоставляют полноценное API с высоким разрешением, нередко используется эмуляция данных с помощью систем опроса открытых источников. Такой подход демонстрирует гибкость архитектуры, позволяя тестировать и отлаживать бизнес-логику без зависимости от внешних платных сервисов.
На стороне обработки данных Apache Flink выступает как мощный движок с поддержкой состоянием и семантикой времени событий. Использование watermark-стратегий позволяет корректно учитывать задержки и перестановки в приходящих сообщениях, что особенно важно для финансовых приложений, где точность временных меток напрямую влияет на корректность вычисленных показателей. Обработка ведётся через потоковые окна с фиксированным временем, в которых рассчитываются логарифмические доходности активов. Такой способ анализа обеспечивает сглаживание рыночного шума и формирует основы для обновления статистики портфеля. Важнейшей частью решения является агрегирование и обновление параметров риска и доходности.
При помощи алгоритма Вельфорда система непрерывно корректирует матрицу ковариаций и вектор ожидаемой доходности, основываясь на новых наблюдениях лог-доходностей. Это обеспечивает устойчивость расчетного ядра, способного быстро реагировать на изменения рыночных условий без потери точности данных. Дальнейшая интеграция потоков с текущими весами портфеля и обновлёнными статистическими данными производится в Flink, где в режиме настоящего времени рассчитываются метрики эффективности, главным образом, коэффициент Шарпа. Этот показатель служит триггером для включения алгоритмов перенастройки портфеля. Управление состоянием объектов реализовано с помощью ValueState, что обеспечивает сохранение промежуточных данных на уровне конкретных ключей (например, идентификатора портфеля), повышая производительность и позволяя быстро восстанавливаться после сбоев.
Для более высокой автоматизации и глубокой оптимизации применяется интеграция с Python-компонентом, использующим библиотеку PyPortfolioOpt. Когда коэффициент Шарпа падает ниже заданного порогового значения, инициируется процесс итеративного переопределения весов активов. Процедура предусматривает несколько подходов, таких как максимизация коэффициента Шарпа, оптимизация риска при заданной доходности и случайные возмущения параметров с целью избежания локальных оптимумов. Это обеспечивает более разнообразный и устойчивый портфель, что особенно ценно при нестабильности рынка. Оптимизированные веса затем сериализуются по схемам AVRO и отправляются в Kafka, где система Flink снова воспринимает их как новые актуальные параметры, замыкая полный цикл потокового анализа и управления.
Такой подход обеспечивает динамическое саморегулирование портфеля, снижая необходимость вмешательства человека и минимизируя задержки в реакции на изменения рынка. Мониторинг состояния системы и визуализация ключевых метрик происходит с помощью интеграции InfluxDB и Grafana. Это даёт возможность в реальном времени отслеживать распределение весов, колебания риска и эффективность портфеля. Благодаря широким возможностям настройки уведомлений в Grafana инвесторы могут оперативно получать сигналы о необходимости пересмотра стратегии или других действий. Кроме того, архитектура поддерживает масштабируемость и гибкость благодаря контейнеризации и оркестрации компонентов через Kubernetes.
Подобные технические решения позволяют обеспечивать отказоустойчивость, упрощают обновление компонентов и создают основу для будущего развертывания в облачных инфраструктурах, таких как AWS Managed Kafka и Flink на EC2. Это особенно актуально для систем, которым требуется высокая доступность и максимальная производительность при работе с большими объёмами финансовых данных. В заключение стоит отметить, что интеграция Apache Kafka и Flink для управления активами в реальном времени является эффективным инструментом для современного инвестора и управляющего фондом. Использование потоковых технологий позволяет не только улучшить качество анализа с минимальными задержками, но и автоматизировать принятие решений в условиях быстро меняющихся рыночных условий. Такой подход снижает риски и повышает общую прибыльность портфеля.
Подобные решения становятся особенно актуальными для развивающихся рынков, где отсутствует полноценная инфраструктура для высокочастотного трейдинга, однако существует потребность в современных аналитических инструментах. Развитие технологий и доступность открытых платформ дают возможность создавать гибкие, масштабируемые и адаптивные системы, способные повышать конкурентоспособность инвесторов и финансовых организаций в эпоху цифровой трансформации. Через объединение потоковых систем данных и алгоритмов оптимизации портфеля формируется новая производительная экосистема управления активами будущего.