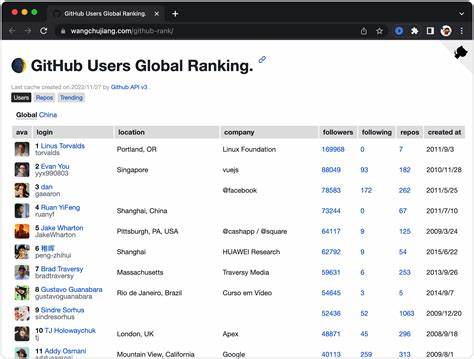
В последние годы Apache Iceberg привлек значительное внимание в мире больших данных благодаря своей способности эффективно управлять историей версий, обеспечивать атомарные операции и оптимизировать работу с огромными наборами данных. Это современный проект, разработанный для работы с распределёнными файловыми системами в экосистемах Hadoop и облачных хранилищах. Однако Iceberg существенно отличается от традиционных реляционных систем управления базами данных (СУБД), которые давно служат фундаментом корпоративных приложений. Задумывались ли вы, что случилось бы, если бы Apache Iceberg стал чувствовать себя как реляционная СУБД? Как изменился бы пользовательский опыт, возможности и эффективность работы с данными? В этом материале мы рассмотрим гипотетический сценарий, в котором Iceberg обретает черты реляционных баз данных и что это значит для индустрии хранения и обработки данных. Прежде всего, стоит подчеркнуть, что Apache Iceberg изначально создавался для решения проблем масштабируемого хранения данных и наследия старых систем типа Hive.
Его архитектура базируется на концепции таблиц с поддержкой версионирования и ACID-транзакций на уровне набора данных, а не отдельных записей. С другой стороны, традиционные реляционные СУБД фокусируются на структурированных данных, сложных запросах SQL и строгих гарантиях консистентности. Если представить, что Iceberg получил бы полноценный реляционный слой, это означало бы интеграцию функций, характерных для СУБД, таких как полноценные схемы, индексы, планировщики запросов и поддержка процедур хранения. Это кардинально изменило бы ландшафт использования Apache Iceberg и дало бы возможность совмещать масштабируемость и гибкость больших данных с мощью классического реляционного анализа. Одним из главных преимуществ подобного слияния стала бы возможность использования Iceberg в транзакционных системах, которые требуют мгновенного обновления данных и строгой консистентности.
Обычные реляционные СУБД обеспечивают быстрый отклик благодаря хорошо развитым оптимизациям запросов и системам кеширования. Обеспечение похожей производительности в распределённой среде, характерной для Iceberg, могло бы стать прорывом в обработке и анализе больших данных. Ещё одним аспектом стало бы расширение возможностей по обеспечению безопасности и управлению пользовательским доступом. Традиционные СУБД часто предоставляют развитые механизмы аутентификации, авторизации и разграничения прав доступа до уровня строк или столбцов. Интеграция подобных функций в Iceberg позволила бы организациям более эффективно контролировать, кто и какие данные может видеть и изменять.
В дополнение к этому, ощущение Iceberg как реляционной СУБД открыло бы новые горизонты для разработчиков и аналитиков. Их привычные инструменты и методологии работы с данными, ориентированные на SQL, могли бы бесшовно применяться к данным, хранящимся в Iceberg. Следовательно, многие процессы ETL и аналитические задачи получили бы оптимизацию и упрощение, что способствовало бы более быстрой генерации бизнес-выводов. Необходимо также выделить вызовы, которые появились бы при такой трансформации. Во-первых, архитектура Iceberg основана на файловых системах и распределённом хранении, что затрудняет реализацию сложных транзакций и мгновенной консистентности на уровне строки.
Кроме этого, индексация и оптимизация доступа к данным в стилях реляционных баз данных требуют дополнительных ресурсов и технологий, которые сегодня реализованы лишь частично. Следовательно, внедрение функционала полноценной СУБД в Iceberg потребовало бы серьёзных инженерных усилий и переосмысления самого принципа работы с данными в таких системах. Тем не менее, уже сегодня мы наблюдаем тенденцию к расширению возможностей Iceberg, например, поддержка ACID-транзакций и работа с интеграцией SQL-запросов средствами движков, таких как Spark и Presto. Такой прогресс является шагом к более тесной интеграции Iceberg с концепциями реляционных баз данных. Можно смело предположить, что дальнейшее развитие проекта предоставит пользователям всё более удобный и мощный инструмент, способный совмещать лучшие качества обеих парадигм.