В современном мире искусственный интеллект и большие языковые модели (LLM) стремительно внедряются во все сферы жизни и бизнеса. От финансовых сервисов до образовательных платформ — технологии, основанные на генеративном ИИ, становятся неотъемлемой частью ежедневной работы и обслуживания пользователей. Однако с растущей зависимостью от таких моделей появляются и новые проблемы, связанные с их эксплуатацией. Среди главных — высокая стоимость использования, задержки отклика и ограничения, накладываемые API-провайдерами. В этих условиях особое значение приобретает концепция семантического кэширования, позволяющая оптимизировать работу с запросами к LLM, повысить скорость ответа и сократить расходы на вычислительные ресурсы.
Суть семантического кэширования заключается в том, что разные формулировки одного и того же вопроса или запроса могут получать одинаковый ответ. Если система способна понять и обработать смысловую близость между запросами, она может повторно использовать ранее сгенерированные ответы, тем самым исключая необходимость в дополнительном обращении к модели искусственного интеллекта. Такой подход не только снижает использование токенов, за которые приходится платить, но и сводит к минимуму задержки в ответах — время ожидания клиента сокращается практически до нуля. Для практической проверки эффективности семантического кэширования был проведен эксперимент с использованием реальных данных из сайта Quora, известного площадки для вопросов и ответов. Этот выбор обусловлен тем, что Quora предлагает огромный массив пользовательских запросов, которые содержат естественные ошибки, грамматические неточности и выражают разнообразные стили речи.
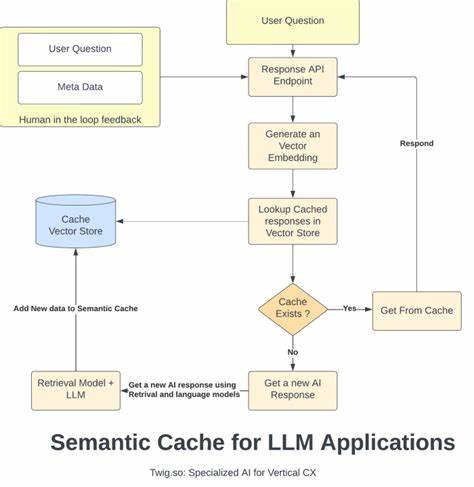
Более того, в датасете Quora есть пометки о дубликатах вопросов, что позволяет объективно оценить степень семантической идентичности между формулировками. Эксперимент проходил с помощью разработанного открытого инструмента Semcache, нынешнего промежуточного программного слоя между клиентом и API модели LLM. Semcache действует как прокси-сервер, принимающий запросы, пересылающий их в LLM API и кэширующий полученные ответы. При получении нового запроса происходит вычисление векторного представления текста с помощью модели sentence-transformers/all-MiniLM-L6-v2. Далее вычисляется косинусное сходство между новым запросом и уже сохраненными в кэше векторами.
Если схожесть превышает установленный порог (в эксперименте порог был равен 0.9), система классифицирует запрос как совпадение и отдает клиенту кэшированный ответ. В ходе эксперимента было отправлено около 20 тысяч вопросов, из которых 28% запросов удалось распознать как схожие с уже имеющимися в кэше. Это позволило снизить нагрузку на сервер LLM, уменьшить количество исходящих запросов и увеличить скорость обслуживания пользователей в 165 раз — среднее время ответа на кэшированные запросы составляло всего 0.010 секунды вместо 1.
648 секунды для необработанных. Интересно отметить, что Semcache работал на достаточно скромном сервере AWS t2.micro, что доказывает экономичность и доступность этой технологии даже для маломасштабных проектов. Память, выделенная для кэша, выросла примерно с 160 до 201 мегабайта после того, как было сохранено около 5,5 тысяч уникальных пар запросов и ответов. Это свидетельствует о том, что при памяти в 8 гигабайт можно кэшировать свыше миллиона таких пар, что обеспечивает масштабируемость решения.
Несмотря на впечатляющие результаты, семантическое кэширование не лишено вызовов. Главная сложность кроется в понимании, когда разные вопросы действительно имеют идентичный смысл и могут быть удовлетворены одним и тем же ответом, а когда они, несмотря на похожесть, требуют уникального обращения к модели. Примером служат вопросы «Из чего сделана пепперони?» и «Что входит в состав пепперони?», которые были классифицированы Quora как разные, но в глазах обычного пользователя и семантической модели воспринимаются как синонимы. Аналогично, вопросы об «эластичном спросе» и «методах измерения эластичности спроса» часто вызывают разногласия в классификации. Выбор модели для создания векторных эмбеддингов играет ключевую роль.
Универсальная модель all-MiniLM-L6-v2 показала хорошие результаты, однако отраслевые или кастомизированные решения могут еще лучше учитывать специфику запросов и снизить долю ложных попаданий. Кроме того, возможность регулируемой настройки порога сходства дает гибкость в адаптации системы под разные кейсы и бизнес-цели. Практическая польза от внедрения семантического кэширования очевидна. Она не ограничивается только сокращением расходов на использование облачных ИИ-сервисов. Высокая скорость отклика улучшает пользовательский опыт, делая интерфейс более отзывчивым и удобным.
Более того, накопленная база кэшированных ответов становится своего рода корпоративной памятью, независимой от конкретного провайдера облачных услуг. Это критически важно в условиях нестабильности сервисов, где доступ к API может быть ограничен или приостанавливаться. В перспективе технологию семантического кэширования можно рассматривать как фундаментальный элемент инфраструктуры крупных AI-приложений. Она позволяет выстроить многослойную систему обработки запросов, в которой простые и часто повторяющиеся вопросы обслуживаются мгновенно и бесплатно, а уникальные или сложные — направляются непосредственно к ИИ. Такой подход не только экономит дорогостоящие вычислительные ресурсы, но и позволяет интеллектуально масштабировать платформы, обслуживающие широкую аудиторию.
Для желающих опробовать семантическое кэширование на практике существует готовый инструмент Semcache с открытым исходным кодом, доступный на Github. Проект активно развивается и даже имеет версию в облаке, которая снимает с пользователя необходимость заботиться о настройке и сопровождении инфраструктуры. Таким образом, разработчики могут сосредоточиться на создании функционала и логике своих приложений, а не на технических деталях кэширования и обработки эмбеддингов. Итогом эксперимента становится подтверждение того, что семантическое кэширование — это не просто техническая новинка, а мощный способ оптимизации взаимодействия с большими языковыми моделями. При правильном подходе и адаптации под конкретные задачи оно способно значительно уменьшить затраты, повысить производительность и даже повысить надежность систем.
В быстро меняющемся мире ИИ такой инструмент даст конкурентное преимущество компаниям, стремящимся максимально эффективно использовать потенциал технологий. Таким образом, использование вопросов из Quora для тестирования и демонстрации возможностей семантического кэширования стало важным этапом в развитии методов оптимизации больших языковых моделей. Это доказало жизнеспособность и актуальность технологии в реальных условиях, подчеркнув ее роль в продвижении искусственного интеллекта к повсеместному внедрению и массовому применению.