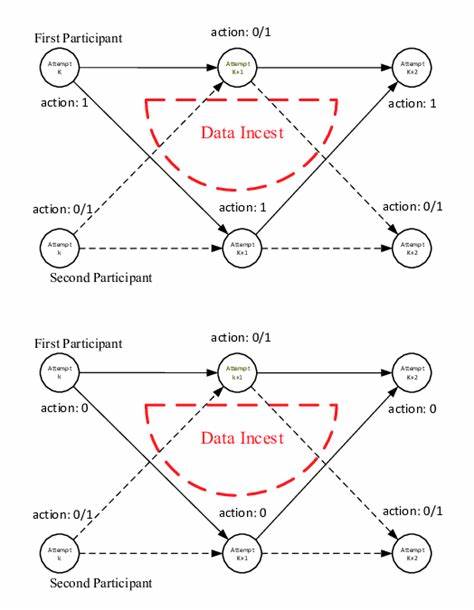
В мире искусственного интеллекта и машинного обучения нарастает тревожная тенденция, известная как «данные инцеста». Это понятие обозначает ситуацию, когда AI-модели обучаются на контенте, сгенерированном ими же самими или другими AI, что создает бесконечный замкнутый круг. На первый взгляд может показаться, что большая часть контента, созданного искусственным интеллектом, достаточно качественная, грамматически корректная и порой даже содержательная. Однако когда такой контент становится частью обучающей выборки, начинается фатальный процесс деградации качества моделей. Подобно змее, поедающей собственный хвост, AI погружается в себя, теряя связь с реальным миром и фактами.
К чему это приводит и почему важно понимать опасность «данных инцеста»? Прежде всего, стоит осознать, что большая часть современных языковых моделей обучается на огромных корпусах текстов, включающих книги, статьи, посты в социальных сетях и иные формы человеческой коммуникации. Однако постоянно растущий объем AI-сгенерированного контента, попадающего в открытый доступ, постепенно становится частью новых данных для обучения, тем самым вводя «данные инцест» в процесс. В результате ИИ начинает «верить» собственной информации, даже если она искажена, непроверена или ошибочна. Этот феномен называют модельным коллапсом — постепенным ухудшением качества генерации и потерей способности к созданию оригинального и достоверного контента. Последствия этого явления выходят далеко за пределы технических аспектов разработки ИИ.
Для обычных пользователей и всей мировой сети это угроза информационному пространству. Воображаемое будущее, в котором львиная доля материалов в интернете создается ИИ, уже не кажется фантастикой. При таком раскладе обучения новых моделей на предварительно сгенерированном AI контенте возникает порочный круг, что приближает интернет к состоянию эхо-камеры, где сходная, однообразная и все менее точная информация доминирует, вытесняя человеческое творчество и разнообразие идей. Не менее опасным становится усиление искажений и предвзятостей. Модели уже наследуют пристрастия из своих тренировочных наборов, часто отражающие социальные стереотипы и ошибочные представления.
При обучении на собственных ошибках, эти предубеждения только множатся. Например, если AI склонен к созданию контента, наполненного гендерными стереотипами или политическими уклонами, «данные инцеста» закрепляют и углубляют эти явления до карикатурной степени. Влияние таких предвзятостей проявляется не только косвенно, но и может менять восприятие реальности, формируя искаженное мировоззрение у пользователей. Другим большой проблемой становится утрата «первопричины» — достоверных, основанных на реальности данных. С каждым новым циклом обучения на искусственно сгенерированных материалах связь ИИ с фактами ослабевает.
В результате тексты, хоть и звучащие убедительно и связно, становятся полны выдумок, ошибок и заблуждений — гипотетический пример - эссе об историческом событии, где Наполеон якобы вторгся на Луну, может показаться забавным, но подобные сведения способны негативно влиять на восприятие информации. Учитывая уже существующие мифы и теории заговора, устойчивость к ложным фактам становится еще более важной задачей. Как мы оказались в такой ситуации? Массовый рост AI-сгенерированного контента — это лишь часть объяснения. Платформы, интернет-ресурсы, и даже специализированные дата-сеты, используемые для обучения узкоспециализированных моделей, содержат значительный процент AI-производных текстов. Например, при обучении модели для юридических документов могут попадать автоматизированно сгенерированные правовые тексты, что со временем ведет к тому, что модели растут в замкнутом круге, воспроизводя свои собственные формулировки, но теряя разнообразие и нюансы исходных данных.
Эта «генетическая» изоляция приводит к снижению универсальности и актуальности моделей. В свете этих бесспросно тревожных факторов возникает вопрос: какие меры могут помочь остановить или хотя бы замедлить это разрушительное явление? Основу противодействия составляет тщательный отбор и проверка данных для обучения. Включение исключительно качественного, разнообразного и преимущественно человеческого контента позволяет сохранить баланс и «привязать» модели к реальности. Аналогия с заботой о саде здесь очень уместна: регулярное удаление «сорняков» — некачественных или сгенерированных ИИ материалов — поддерживает здоровье и продуктивность «растущих растений» — самих AI-моделей. Важную роль играет постоянное обновление баз данных с использованием свежих и достоверных источников: книг, серьезных исследований, проверенных новостей и экспертных мнений.
Этот «дыхательный» цикл обеспечивает моделям доступ к новым знаниям, снижая эффект замыкания на собственных ошибках. Такой подход помогает поддерживать творческий потенциал, точность и разнообразие создаваемого контента. Новейшие технологии обнаружения AI-созданного текста также становятся незаменимыми инструментами. Системы, похожие на спам-фильтры, способны отсеивать автоматически сгенерированные материалы из тренировочных наборов. Это способствует предотвращению дальнейшего распространения «данных инцеста» и сохранению чистоты и оригинальности обучающих выборок.
Кроме того, участие человека в процессе обучения, оценки и корректировки моделей остается важным. Практика «обучения с подкреплением на основе обратной связи от человека» (RLHF) помогает моделям лучше ориентироваться в сложных и неоднозначных ситуациях, снижая вероятность искажений. Однако с ростом объемов AI-контента полная зависимость от ручного труда становится непрактичной, что требует внедрения автоматизированных и гибридных методов контроля качества. Необходимо также регулярное тестирование и аудит моделей, чтобы выявлять первые признаки ухудшения качества и искажений. Это базируется на системном анализе результатов генерации, сравнения с эталонами и текущими знаниями, а также проверке устойчивости к различным видам сбоев.
Без такой внимательной работы последствия «данных инцеста» могут оставаться незамеченными вплоть до резкого снижения общей эффективности ИИ. В заключение стоит подчеркнуть, что проблема «данных инцеста» — критический вызов для развития искусственного интеллекта. Она поднимает вопросы об этике, надежности и долговременной устойчивости технологий, с которыми сегодня взаимодействуют миллионы людей по всему миру. Если не предпринять своевременных мер, информационное пространство может стать замкнутым, однообразным и наполненным ошибками, что ослабит доверие к AI и поставит под сомнение его пользу. Тем не менее, существует множество путей, способных помочь избежать этой угрозы.
От внимательного отбора данных и регулярного обновления до современных систем детекции и участия человека в обучении — все эти практики вместе могут создать среду, в которой искусственный интеллект будет развиваться правильно, оставаясь союзником человека и инструментом для обогащения знаний и творчества. Пользователям стоит помнить, что за маской убедительного и «умного» контента может скрываться плод бесконечного круговорота одних и тех же алгоритмов. Осознанность и критическое мышление — лучшие защитники от искаженной информации, которую приносит с собой эпоха «данных инцеста». Такой подход поможет не только сохранить качество и оригинальность AI-продуктов, но и сохранить доверие к технологиям будущего.