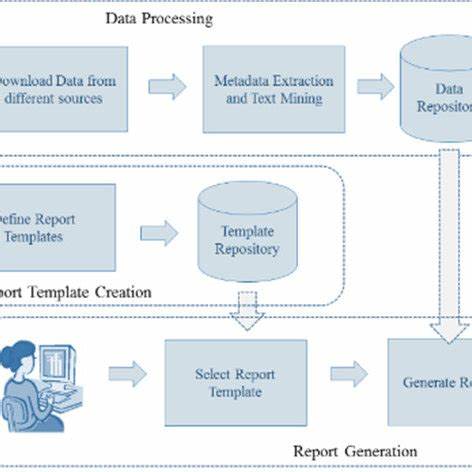
Тема: Моделирование тем с автоматическим определением количества тем В современном мире, где объем информации растет с каждым днем, эффективность обработки данных становится важной задачей для ученых и бизнесменов. Одним из наиболее перспективных направлений в обработке текстовых данных является моделирование тем, которое позволяет выявлять скрытые структуры в больших массивах текстовой информации. Особенно интересно использование автоматизированных методов для определения числа тем, что значительно упрощает процесс анализа и улучшает его качество. Моделирование тем основано на статистических методах, которые позволяют разделить текстовые документы на группы, содержащие похожие темы. В качестве одного из самых популярных методов используется латентное дирихлеево распределение (LDA).
Этот подход подходит для работы с неструктурированными данными, такими как статьи, блоги, посты в социальных сетях и другие текстовые массивы. Процесс моделирования тем с использованием LDA состоит из нескольких этапов. Во-первых, необходимо подготовить данные. Это включает в себя очистку текстов, удаление стоп-слов, нормализацию слов (например, перевод их в нижний регистр), а также создание матрицы документов и терминов. Такой подход позволяет выделить наиболее значимые слова и, следовательно, темы, которые в них содержатся.
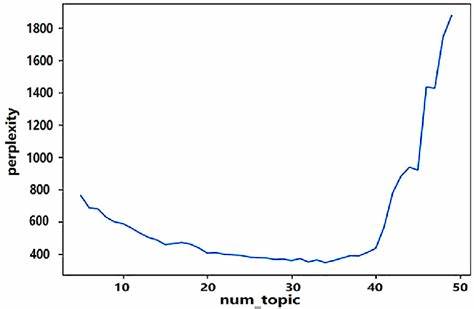
Одной из сложных задач, с которой сталкиваются исследователи, является определение оптимального количества тем в наборе данных. Это вопрос может серьезно повлиять на качество анализа: слишком малое или слишком большое количество тем может привести к искажению результатов. Автоматизация этого процесса становится необходимостью, и здесь на помощь приходят различные метрики, позволяющие оценить качество моделирования. Существуют различные метрики, которые используются для определения оптимального количества тем. Среди них можно выделить такие, как метрика Гриффитса (Griffiths2004), метрика Цао и Жуани (CaoJuan2009) и метрика Аруна (Arun2010).
Каждая из этих метрик имеет свои особенности и может давать разные результаты в зависимости от специфики данных. Например, метрика Цао и Жуани фокусируется на оценке качества распределения вероятностей по темам, тогда как метрика Аруна рассматривает распределение вероятностей в контексте структурной схожести тем. Процесс автоматизации определения количества тем требует сложных вычислений, которые могут быть наилучшим образом выполнены посредством параллельной обработки. Использование нескольких ядер процессора позволяет значительно ускорить вычисления и повысить общую эффективность анализа. Теперь исследователям не нужно ждать часы и дни, чтобы получить нужные результаты; их можно получить за считанные минуты, а порой и секунды.
После того как было определено оптимальное количество тем, следующий этап — это визуализация результатов. Визуализация играет ключевую роль в интерпретации тем. Она позволяет исследователям и бизнесменам быстро понять, о чем идет речь в документе, и какие основные темы могут быть интересны для дальнейшего изучения. Для этого можно использовать такие библиотеки, как LDAvis, которые предлагают интерактивные графики и диаграммы, позволяющие исследователям глубже анализировать взаимосвязи между темами и ключевыми словами. Почему же автоматизированное моделирование тем с использованием LDA стало столь популярным? Во-первых, это связано с увеличением объемов данных, которые необходимо обрабатывать.
Научные исследования, корпоративные отчеты, отзывы потребителей — все эти документы содержат ценную информацию, которую можно извлечь и проанализировать. Моделирование тем позволяет находить закономерности и связи, которые могут быть неочевидны на первый взгляд. Во-вторых, автоматизация процесса позволяет сократить время и усилия, необходимые для анализа данных. Ранее исследователям приходилось вручную просматривать и анализировать документы, что требовало значительных затрат времени и ресурсов. Сегодня с помощью автоматизированных инструментов можно быстро обрабатывать большие объемы информации и получать результаты, которые ранее были недоступны.
В-третьих, моделирование тем помогает выявить новые бизнес-возможности и направления для развития. Например, компании могут использовать методы анализа тем для исследования мнений своих клиентов, понимания их потребностей и ожиданий. Это позволяет компаниям адаптировать свою стратегию и улучшать свои продукты и услуги. Тем не менее, несмотря на все преимущества, автоматическое моделирование тем имеет и свои недостатки. Одним из основных является сложность интерпретации результатов.
Иногда модели могут создавать темы, которые не имеют четкой связи с реальными значениями в тексте, что может вводить в заблуждение. Кроме того, выбор метрики для определения оптимального количества тем также может значительно повлиять на результаты, поэтому необходимо быть осторожным в этом процессе. В заключение, моделирование тем с автоматизированным определением числа тем является мощным инструментом для анализа больших объемов текстовой информации. Этот подход позволяет исследователям и бизнесменам быстро получать результаты и выявлять скрытые закономерности в текстах. С каждым днем технология продолжает развиваться, привнося новые методы и инструменты, которые делают анализ данных более эффективным и доступным.
Какую же роль может сыграть автоматизированное моделирование тем в будущем? С учетом роста объемов данных, необходимость в эффективных методах анализа будет только увеличиваться. Возможности, которые открываются перед нами благодаря рассекречиванию данных и внедрению новых технологий анализа, могут кардинально изменить подход к обработке информации. С учетом текущих тенденций можно ожидать, что в ближайшие годы мы увидим дальнейшее развитие автоматизированного моделирования тем, что позволит нам лучше понимать и использовать информацию, которая нас окружает.