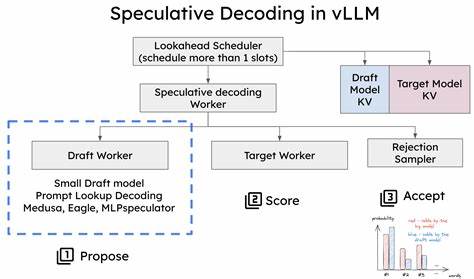
В современном мире искусственного интеллекта и обработки естественного языка (NLP) одной из ключевых задач является ускорение инференса больших языковых моделей (LLM) без ущерба для качества предсказаний. В связи с увеличением размеров моделей и разнообразием используемых словарей возникают новые вызовы для алгоритмов декодирования. Одним из перспективных направлений считается разработка быстрых спекулятивных алгоритмов декодирования, ориентированных на работу с гетерогенными словарями. Эти технологии открывают новые возможности для повышения скорости и эффективности работы LLM, что в свою очередь способствует более широкому применению ИИ в различных сферах, от автоматического перевода и генерации текста до научных исследований и бизнеса. Спекулятивное декодирование представляет собой метод, при котором генерация следующего слова запускается заранее на основе вероятных предположений, позволяя значительно снизить время отклика системы.
Классические алгоритмы работают с монотонными, однородными словарями, что ограничивает гибкость и адаптивность моделей к конкретным задачам и языковым особенностям. Однако, гетерогенные словари, включающие в себя множество разнообразных подмножества слов и символов, требуют более продвинутых подходов. Инновационные алгоритмы, адаптированные для гетерогенных словарей, способны эффективно управлять разнообразием и разнородностью данных, что обеспечивает оптимизацию процесса декодирования даже при высокой сложности модели. Одной из ключевых особенностей этих алгоритмов является способность выполнять «безубыточное» спекулятивное декодирование. Это означает, что ускорение не сопровождается потерей качества выходного текста или снижением точности предсказаний.
Важной задачей разработчиков является сохранение баланса между скоростью и точностью, и современные методы именно это и обеспечивают. Технически быстрые спекулятивные алгоритмы используют параллельные вычисления и прогнозные модели, чтобы предварительно вычислять вероятные варианты продолжения текста. Они динамически выбирают наиболее подходящие варианты из гетерогенного словаря, минимизируя необходимость повторных вычислений и корректировок. Такая архитектура позволяет добиться значительного сокращения времени генерации текста в реальном времени, что особенно важно для приложений с ограниченными ресурсами или высоким уровнем требовательности к задержкам. Особенно ценно применение этих методик в распределённых системах и облачных платформах, где оптимизация вычислительных ресурсов и снижение затрат напрямую влияет на коммерческую эффективность сервисов.
Исследования, проведённые в рамках конференций по машинному обучению, таких как ICML, подтверждают высокую эффективность данных алгоритмов. Применение спекулятивного декодирования для гетерогенных словарей позволяет реализовывать модели, способные к более глубокому пониманию и генерации текстов на разных языках и диалектах, учитывая специфику различных областей применения. Помимо повышения производительности, это способствует улучшению качества пользовательского опыта, так как модели начинают работать быстрее и точнее. В перспективе технологии быстрых спекулятивных алгоритмов декодирования могут стать стандартом для построения современных языковых моделей, внедряясь как в академические исследования, так и в коммерческие продукты. Выпуск обновлённых библиотек и SDK, ориентированных на использование таких алгоритмов, позволит разработчикам сосредоточиться на создании инновационных приложений, а не на оптимизации базовых процессов обработки текста.
На сегодняшний день, интеграция этих подходов уже делает возможным появление новых сервисов, таких как интеллектуальные помощники, системы автоматического реферирования и персонализированные генераторы контента, которые работают быстрее и точнее, благодаря оптимизированному декодированию на уровне ядра модели. В результате, быстрые спекулятивные алгоритмы декодирования для гетерогенных словарей не просто ускоряют работу ИИ, но и повышают его адаптивность, расширяя спектр задач, которые может решать искусственный интеллект. Этот прогресс открывает новое окно возможностей для бизнеса, науки и повседневной жизни, делая коммуникацию с машинами более гладкой и естественной. Таким образом, с учетом растущих потребностей в масштабируемых и высокопроизводительных решениях, разработка подобных алгоритмов является ключевым направлением современного NLP. Они становятся фундаментом для следующего поколения языковых моделей, поддерживая баланс между вычислительной эффективностью и качеством генерации текста.
Учитывая динамику развития технологий и возрастающую сложность моделей, сфера спекулятивного декодирования для гетерогенных словарей обещает стать одним из самых востребованных направлений в ближайшие годы.